NNStreamer
Overview
NNStreamer is a set of GStreamer plugins that allow GStreamer developers to adopt neural network models, and neural network developers to manage neural network pipelines with their filters in a easy and efficient way.
It provides the new GStreamer stream data type and a set of GStreamer elements (plugins) to construct media stream pipeline with neural network models. It supports various well-known neural network frameworks including Tensorflow, Tensorflow-lite, Caffe2, PyTorch, OpenVINO and ArmNN. All the details are well-documented on the NNStreamer Official Documentation.
Users may include custom C functions, C++ objects, or Python objects as well as such frameworks as neural network filters of a pipeline in run-time and also add and integrate support for such frameworks or hardware AI accelerators in run-time, which may exist as independent plugin binaries.
Important
IoT Yocto only have demo examples for Tensorflow-lite backend and MTK Neuron backend due to the machine learning software stack limitation.
Here comes the illustration of software stack for the NNStreamer on IoT Yocto.
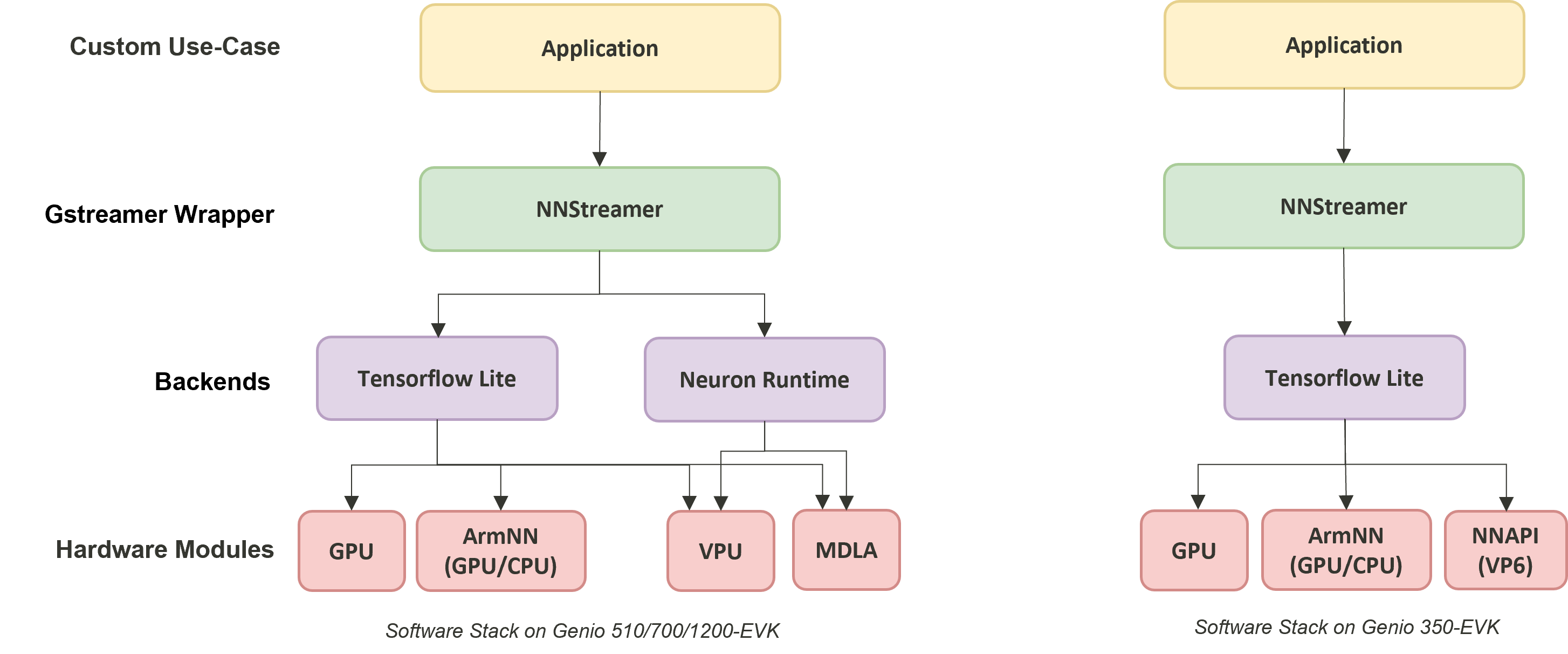
NNStreamer on IOT Yocto
The software stack for machine learning on IoT Yocto provides various backend-accelerator approach for the developer. User will be able to run the inference with online Neuron Stable Delegate on MTK’s powerful APU.
Software Stack |
Backend |
Genio 350-EVK |
Genio 510-EVK |
Genio 700-EVK |
Genio 1200-EVK |
Tensorflow-Lite |
CPU |
V |
V |
V |
V |
Tensorflow-Lite + GPU delegate |
GPU |
V |
V |
V |
V |
Tensorflow-Lite + ARMNN Delegate |
GPU, CPU |
V |
V |
V |
V |
Tensorflow-Lite + NNAPI Delegate |
VPU |
V |
X |
X |
X |
Tensorflow-Lite + Neuron Stable Delegate |
MDLA, VPU |
X |
V |
V |
V |
Neuron SDK |
MDLA, VPU |
X |
V |
V |
V |
NNStreamer::tensor_filter
The NNStramer plugin - tensor_filter plays a important role on the whole NNStreamer project.
It acts as a bridge between GStreamer data stream and neural network frameworks such as
Tensorflow-lite,
which process the data stream to be the neural-network-accepted format and also run the model inference.
Like a typical GStreamer plugin, the command gst-inspect-1.0 will show the details of plugin information for tensor_filter:
gst-inpsect-1.0 tensor_filter
...
Pad Templates:
SINK template: 'sink'
Availability: Always
Capabilities:
other/tensor
framerate: [ 0/1, 2147483647/1 ]
other/tensors
format: { (string)static, (string)flexible }
framerate: [ 0/1, 2147483647/1 ]
SRC template: 'src'
Availability: Always
Capabilities:
other/tensor
framerate: [ 0/1, 2147483647/1 ]
other/tensors
format: { (string)static, (string)flexible }
framerate: [ 0/1, 2147483647/1 ]
Element has no clocking capabilities.
Element has no URI handling capabilities.
Pads:
SINK: 'sink'
Pad Template: 'sink'
SRC: 'src'
Pad Template: 'src'
Element Properties:
accelerator : Set accelerator for the subplugin with format (true/false):(comma separated ACCELERATOR(s)). true/false determines if accelerator is to be used. list of accelerators determines the backend (ignored with false). Example, if GPU, NPU can be used but not CPU - true:npu,gpu,!cpu. The full list of accelerators can be found in nnstreamer_plugin_api_filter.h. Note that only a few subplugins support this property.
flags: readable, writable
String. Default: ""
custom : Custom properties for subplugins ?
flags: readable, writable
String. Default: ""
framework : Neural network framework
flags: readable, writable
String. Default: "auto"
input : Input tensor dimension from inner array, up to 4 dimensions ?
flags: readable, writable
String. Default: ""
input-combination : Select the input tensor(s) to invoke the models
flags: readable, writable
String. Default: ""
inputlayout : Set channel first (NCHW) or channel last layout (NHWC) or None for input data. Layout of the data can be any or NHWC or NCHW or none for now.
flags: readable, writable
String. Default: ""
inputname : The Name of Input Tensor
flags: readable, writable
String. Default: ""
inputranks : The Rank of the Input Tensor, which is separated with ',' in case of multiple Tensors
flags: readable
String. Default: ""
inputtype : Type of each element of the input tensor ?
...
Tensorflow-Lite Framework
Users can be able to construct GStreamer streaming pipeline by using the existing tensor_filter_tensorflow_lite. Examples of using the Tensorflow-Lite framework can be found in NNStreamer-Example.
Some properties like neural network framework and model path are required by user input when you are like to use tensor_filter_tensorflow_lite.
But there is no need to pass the model meta information such as input/output type and input/output dimension because these properties in the model are
properly handled by the tensor_filter_tensorflow_lite.
Here is an pipeline snippets for tensor_filter using Tensorflow-Lite framework. Please visit NNStreamer-Example to get full examples.
... tensor_converter ! \
tensor_filter framework=tensorflow-lite model=/usr/bin/nnstreamer-demo/mobilenet_v1_1.0_224_quant.tflite custom=NumThreads:8 ! \
...
Neuron Framework
IoT Yocto designed a tensor_filter which supports Neuron SDK. Users can be able to use tensor_filter_neuronsdk to create GStreamer streaming pipeline
that leverage Genio platform’s powerful AI hardware accelerator. The source implementation of the tensor_filter_neuronsdk in IoT Yocto NNStreamer repository
($BUILD_DIR/tmp/work/armv8a-poky-linux/nnstreamer/$PV/git/ext/nnstreamer/tensor_filter/tensor_filter_neuronsdk.cc).
Different from Tensorflow-Lite framework, all the model properties neural network framework, model path also input/output type and input/output dimension are required by user input
when you are like to use tensor_filter_neuronsdk. All the model information are hidden in the DLA file for the security concern, it’s important that user should have
comprehensive realization for their own model.
Here is an pipeline snippets for tensor_filter using the Neuron SDK:
... tensor_converter ! \
tensor_filter framework=neuronsdk model=/usr/bin/nnstreamer-demo/mobilenet_v1_1.0_224_quant.dla inputtype=uint8 input=3:224:224:1 outputtype=uint8 output=1001:1 ! \
...
Note
The tensor_filter properties related to input/output type and dimension are as follows:
inputtype: Type of each element of the input tensor.
inputlayout: Set channel first (NCHW) or channel last layout (NHWC) or None for input data.
input: Input tensor dimension from inner array, up to 4 dimensions.
outputtype: Type of each element of the output tensor.
outputlayout: Set channel first (NCHW) or channel last layout (NHWC) or None for output data.
output: Output tensor dimension from inner array, up to 4 dimensions.
Get more details for tensor_filter from the NNstreamer online document and the source code.
NNStreamer Unit Test
NNStreamer provides gtest based test suite for common library and NNStreamer plugins. Run the unit tests by following command to gain an insight into the integration status of NNStreamer on IoT Yocto.
cd /usr/bin/unittest-nnstreamer/
ssat
...
==================================================
[PASSED] transform_typecast (37 passed among 39 cases)
[PASSED] nnstreamer_filter_neuronsdk (8 passed among 8 cases)
[PASSED] transform_dimchg (13 passed among 13 cases)
[PASSED] nnstreamer_decoder_pose (3 passed among 3 cases)
[PASSED] nnstreamer_decoder_boundingbox (15 passed among 15 cases)
[PASSED] transform_clamp (10 passed among 10 cases)
[PASSED] transform_stand (9 passed among 9 cases)
[PASSED] transform_arithmetic (36 passed among 36 cases)
[PASSED] nnstreamer_decoder (17 passed among 17 cases)
[PASSED] nnstreamer_filter_custom (23 passed among 23 cases)
[PASSED] transform_transpose (16 passed among 16 cases)
[PASSED] nnstreamer_filter_tensorflow2_lite (31 passed among 31 cases)
[PASSED] nnstreamer_repo_rnn (2 passed among 2 cases)
[PASSED] nnstreamer_converter (32 passed among 32 cases)
[PASSED] nnstreamer_repo_dynamicity (10 passed among 10 cases)
[PASSED] nnstreamer_mux (84 passed among 84 cases)
[PASSED] nnstreamer_split (21 passed among 21 cases)
[PASSED] nnstreamer_repo (77 passed among 77 cases)
[PASSED] nnstreamer_demux (43 passed among 43 cases)
[PASSED] nnstreamer_filter_python3 (0 passed among 0 cases)
[PASSED] nnstreamer_rate (17 passed among 17 cases)
[PASSED] nnstreamer_repo_lstm (2 passed among 2 cases)
==================================================
[PASSED] All Test Groups (23) Passed!
TC Passed: 595 / Failed: 0 / Ignored: 2
Some test cases which marked with “Ignored” are not invoked because they didn’t implement runTest.sh in its test directory that is required by ssat.
Though the integration status can be acquired by it’s own unit test execution binary.
Here takes ArmNN unit test as an example.
cd /usr/bin/unittest-nnstreamer/tests/
export NNSTREAMER_SOURCE_ROOT_PATH=/usr/bin/unittest-nnstreamer/
./unittest_filter_armnn
...
[==========] 13 tests from 1 test suite ran. (141 ms total)
[ PASSED ] 13 tests.
NNStreamer Pipeline Examples
IoT Yocto provides some python examples in /usr/bin/nnstreamer-demo/ to demonstrate how to create a NNStreamer pipeline with different configuration on tensor_filters
for various use cases.
The examples are modified from NNStreamer-Example.
Category |
Input Source |
Python script |
Demo Runner |
run_nnstreamer_example.py |
|
Image Classification |
Camera |
nnstreamer_example_image_classification.py |
Object Detection |
Camera |
nnstreamer_example_object_detection.py |
Object Detection |
Camera |
nnstreamer_example_object_detection_yolov5.py |
Pose Estimation |
Camera |
nnstreamer_example_pose_estimation.py |
Face Detection |
Camera |
nnstreamer_example_face_detection.py |
Monocular Depth Estimation |
Camera |
nnstreamer_example_monocular_depth_estimation.py |
Image Enhancement |
Image |
nnstreamer_example_low_light_image_enhancement.py |
Each application could be run separately with it’s own python script but here we strongly suggest that
users run the application via Demo Runner run_nnstreamer_example.py. Users can easily change the target
application by simply modifying argument rather than constructing complicated command.
The remaining part of this section, we are going to use run_nnstreamer_example.py to go through the demo process.
Use --help to list all available options of it.
python3 run_nnstreamer_example.py --help
usage: run_nnstreamer_example.py [-h] [--app {image_classification,object_detection,object_detection_yolov5,face_detection,pose_estimation,low_light_image_enhancement,monocular_depth_estimation}]
[--engine {neuronsdk,tflite,armnn}] [--img IMG] [--cam CAM] --cam_type {uvc,yuvsensor,rawsensor} [--width WIDTH] [--height HEIGHT] [--performance {0,1}]
[--fullscreen {0,1}] [--throughput {0,1}] [--rot ROT]
options:
-h, --help show this help message and exit
--app {image_classification,object_detection,object_detection_yolov5,face_detection,pose_estimation,low_light_image_enhancement,monocular_depth_estimation}
Choose a demo app to run. Default: image_classification
--framework {neuronsdk,tflite}
Choose a framework to run the pipeline. Default: neuronsdk
--engine {armnn,neuron_stable}
Choose a engine for tflite framework to run the pipeline.
If no engine is specified, the inference will run on CPU.
Note 2: neuron_stable is NOT available on Genio-350
--img IMG Input a image file path.
Example: /usr/bin/nnstreamer-demo/original.png
Note: This paramater is dedicated to low light enhancement app
--cam CAM Input a camera node id, ex: 130 .
Use 'v4l2-ctl --list-devices' query camera node id.
Example:
$ v4l2-ctl --list-devices
...
C922 Pro Stream Webcam (usb-11290000.xhci-1.2):
/dev/video130
/dev/video131
...
Note: This paramater was designed for all the apps except low light enhancement app.
--cam_type {uvc,yuvsensor,rawsensor}
Choose correct type of camera being used for the demo, ex: yuvsensor
Note: This paramater was designed for all the apps except low light enhancement app.
--width WIDTH Width for showing on display, ex: 640
--height HEIGHT Height for showing on display, ex: 480
--performance {0,1} Enable to make CPU/GPU/APU run under performance mode, ex: 1
--fullscreen {0,1} Fullscreen preview.
1: Enable
0: Disable
Note: This paramater is for all the apps except low light enhancement app.
--throughput {0,1} Print throughput information.
1: Enable
0: Disable
--rot ROT Rotate the camera image by degrees, ex: 90
Note: This paramater is for all the apps except low light enhancement app.
Here goes some fundamental options:
--framework:IoT Yocto supports
tfliteandneuronsdk, the former is online inference path and the other is offline inference path. Offline inference path is NOT supported on Genio-350. Please find the details in ML section--engine:Choose a engine for
tfliteframework to run the pipeline. It could bearmnn,neuron_stable.For every python demo script, there exists
build_pipelinefunction that will createtensor_filterwith different framework, engine and properties based on user setting.Important
The
--engineflag is designed only for online inference path,tfliteframework, which supports different hardware accelerator for model inference also has fallback mechanism. The offline inference pathneuronsdkcan only run the model inference on APU.Here are some examples for
run_nnstreamer_example.py:--framework tfliteor--framework tflite --engine cpu:If no engine is specified, the inference will run on CPU tensor_filter framework=tensorflow-lite model=/usr/bin/nnstreamer-demo/mobilenet_v1_1.0_224_quant.tflite custom=NumThreads:8--framework tflite --engine armnn:tensor_filter framework=tensorflow-lite model=/usr/bin/nnstreamer-demo/mobilenet_v1_1.0_224_quant.tflite custom=Delegate:External,ExtDelegateLib:/usr/lib/libarmnnDelegate.so.29.0,ExtDelegateKeyVal:backends#GpuAcc--framework tflite --engine stable_delegate:tensor_filter framework=tensorflow-lite model=/usr/bin/nnstreamer-demo/mobilenet_v1_1.0_224_quant.tflite custom=Delegate:Stable,StaDelegateSettingFile:/usr/share/label_image/stable_delegate_settings.json,ExtDelegateKeyVal:backends#GpuAcc
--framework neuronsdk:The details for the framework were mentioned here.
tensor_filter framework=neuronsdk model=/usr/bin/nnstreamer-demo/mobilenet_v1_1.0_224_quant.dla inputtype=uint8 input=3:224:224:1 outputtype=uint8 output=1001:1
--cam: Input a camera node index.--performance:Set performance mode for your platform. Select your current platform and set the performance mode for it. It could be
--performance 0: Set the performance mode off--performance 1: Set the performance mode on
Performance mode will make the CPU, GPU, and APU running at the highest frequency and disable thermal throttling.
Camera-Input Application
A v4l2-compatible device is required for acting as input source for the following demonstrations.
General Configuration
The examples in this section share some common configurations. It means that users can only change the application option without modifying the shared settings.
Here takes USB webcam as an example. To get correct camera node ID, some methods are provided in the Camera Section, such as
v4l2-ctl --list-devices
...
C922 Pro Stream Webcam (usb-11290000.xhci-1.2):
/dev/video130
/dev/video131
...
In this case, the camera node ID is /dev/video130.
The common settings for the UVC-camera with enabling the Performance Mode are shown below:
CAM_TYPE=uvc
CAMERA_NODE_ID=130
MODE=1
Note
Users can choose raw sensor or YUV sensor as a input source by assigning the CAM_TYPE, e.g. CAM_TYPE=rawsensor, CAM_TYPE=yuvsensor.
Image Classification

Python script:
/usr/bin/nnstreamer-demo/nnstreamer_example_image_classification.pyRun example:
Set the variable
APPto Image Classification application:APP=image_classificationChoose the framework you like to leverage on:
Online inference on tensorflow-lite
FRAMEWORK=tfliteOffline inference on neuronsdk
FRAMEWORK=neuronsdk
Choose hardware engine for framework
tensorflow-lite:Please skip this step for framework
neuronsdk.Execute on CPU:
The process will also run on CPU if no engine is specified.
ENGINE=cpuExecute on GPU through ArmNN delegate:
ENGINE=armnnExecute on MDLA through Stable delegate:
ENGINE=stable_delegate
Run the command:
Online inference on tensorflow-lite
python3 /usr/bin/nnstreamer-demo/run_nnstreamer_example.py --app $APP --cam_type $CAM_TYPE --cam $CAMERA_NODE_ID --framework $FRAMEWORK --engine $ENGINE --performance $MODEOffline inference on neuronsdk
Actually this is as same as the above one but eliminating the
--engineargument.python3 /usr/bin/nnstreamer-demo/run_nnstreamer_example.py --app $APP --cam_type $CAM_TYPE --cam $CAMERA_NODE_ID --framework $FRAMEWORK --performance $MODE
Average inference time
Average inference time of nnstreamer_example_image_classification (UVC) CPU
ARMNN GPU
Neuron Stable
NNAPI(VPU)
NeuronSDK
Genio-350
46.3
40
Not Supported
508
Not Supported
Genio-510
8.6
16.5
1.6
Not Supported
2.3
Genio-700
9.4
13
1.3
Not Supported
2.3
Genio-1200
7.3
9
1.8
Not Supported
2.5
Pipeline graph
Here is the GStreamer pipeline defined in the example
nnstreamer_example_image_classification.pywith--cam uvcand--framework neuronsdk. The pipeline graph is generated through thegst-reportcommand fromgst-instrumentstool. The details can be found in Pipeline Profiling:gst-launch-1.0 \ v4l2src name=src device=/dev/video5 io-mode=mmap num-buffers=300 ! video/x-raw,width=640,height=480,format=YUY2 ! tee name=t_raw \ t_raw. ! queue ! textoverlay name=tensor_res font-desc=Sans,24 ! fpsdisplaysink sync=false video-sink="waylandsink sync=false fullscreen=0" \ t_raw. ! queue leaky=2 max-size-buffers=2 ! videoconvert ! videoscale ! video/x-raw,width=224,height=224,format=RGB ! tensor_converter ! \ tensor_filter framework=neuronsdk model=/usr/bin/nnstreamer-demo/mobilenet_v1_1.0_224_quant.dla inputtype=uint8 input=3:224:224:1 outputtype=uint8 output=1001:1 ! \ tensor_sink name=tensor_sink
Object Detection
ssd_mobilenet_v2_coco

Python script:
/usr/bin/nnstreamer-demo/nnstreamer_example_object_detection.pyModel: ssd_mobilenet_v2_coco.tflite
Run example:
Set the variable
APPto Object Detection application:APP=object_detectionChoose the framework you like to leverage on:
Online inference on tensorflow-lite
FRAMEWORK=tfliteOffline inference on neuronsdk
FRAMEWORK=neuronsdk
Choose hardware engine for framework
tensorflow-lite:Please skip this step for framework
neuronsdk.Execute on CPU:
The process will also run on CPU if no engine is specified.
ENGINE=cpuExecute on GPU through ArmNN delegate:
ENGINE=armnnExecute on MDLA through Stable delegate:
ENGINE=stable_delegate
Run the command:
Online inference on tensorflow-lite
python3 /usr/bin/nnstreamer-demo/run_nnstreamer_example.py --app $APP --cam_type $CAM_TYPE --cam $CAMERA_NODE_ID --framework $FRAMEWORK --engine $ENGINE --performance $MODEOffline inference on neuronsdk
Actually this is as same as the above one but eliminating the
--engineargument.python3 /usr/bin/nnstreamer-demo/run_nnstreamer_example.py --app $APP --cam_type $CAM_TYPE --cam $CAMERA_NODE_ID --framework $FRAMEWORK --performance $MODE
Average inference time
Average inference time of nnstreamer_example_object_detection (UVC) CPU
ARMNN GPU
Neuron Steble Delegate
NNAPI(VPU)
NeuronSDK
Genio-350
579
194.5
Not supported
Not supported
Not supported
Genio-510
175
79
21.5
Not supported
22.5
Genio-700
164
60
15.5
Not supported
16.7
Genio-1200
121
39
12.3
Not supported
13
Pipeline graph
Here is the GStreamer pipeline defined in the example
nnstreamer_example_object_detections.pywith--cam uvcand--framework neuronsdk. The pipeline graph is generated through thegst-reportcommand fromgst-instrumentstool. The details can be found in Pipeline Profiling:gst-launch-1.0 \ v4l2src name=src device=/dev/video5 io-mode=mmap num-buffers=300 ! video/x-raw,width=640,height=480,format=YUY2 ! tee name=t_raw \ t_raw. ! queue leaky=2 max-size-buffers=10 ! compositor name=mix sink_0::zorder=1 sink_1::zorder=2 ! fpsdisplaysink sync=false video-sink="waylandsink sync=false fullscreen=0" \ t_raw. ! queue leaky=2 max-size-buffers=2 ! v4l2convert ! videoscale ! video/x-raw,width=300,height=300,format=RGB ! tensor_converter ! tensor_transform mode=arithmetic option=typecast:float32,add:-127.5,div:127.5 ! queue ! \ tensor_filter framework=neuronsdk model=/usr/bin/nnstreamer-demo/ssd_mobilenet_v2_coco.dla inputtype=float32 input=3:300:300:1 outputtype=float32,float32 output=4:1:1917:1,91:1917:1 ! \ tensor_decoder mode=bounding_boxes option1=mobilenet-ssd option2=/usr/bin/nnstreamer-demo/coco_labels_list.txt option3=/usr/bin/nnstreamer-demo/box_priors.txt option4=640:480 option5=300:300 ! queue leaky=2 max-size-buffers=2 ! mix.
YOLOv5

Python script:
/usr/bin/nnstreamer-demo/nnstreamer_example_object_detection_yolov5.pyModel: yolov5s-int8.tflite
Run example:
Set the variable
APPto Object Detection(YOLOv5s) application:APP=object_detection_yolov5Choose the framework you like to leverage on:
Online inference on tensorflow-lite
FRAMEWORK=tfliteOffline inference on neuronsdk
FRAMEWORK=neuronsdk
Note
For offline inference, the YOLOv5 model is only supported on MDLA3.0 (Genio-700/510) , which will got model-converting error on MDLA2.0 (Genio-1200) due to the unsupported operations.
ncc-tflite --arch mdla2.0 yolov5s-int8.tflite -o yolov5s-int8.dla --int8-to-uint8 OP[123]: RESIZE_NEAREST_NEIGHBOR ├ MDLA: HalfPixelCenters is unsupported. ├ EDMA: unsupported operation OP[145]: RESIZE_NEAREST_NEIGHBOR ├ MDLA: HalfPixelCenters is unsupported. ├ EDMA: unsupported operation ERROR: Cannot find an execution plan because of unsupported operations ERROR: Fail to compile yolov5s-int8.tfliteThat’s the reason why users get failure when running
run_nnstreamer_example.py --app object_detection_yolov5on Genio-1200.python3 /usr/bin/nnstreamer-demo/run_nnstreamer_example.py --app object_detection_yolov5 --cam_type uvc --cam 130 --framework neuronsdk --performance 1 ... ERROR: Cannot open the file: /usr/bin/nnstreamer-demo/yolov5s-int8.dla ERROR: Cannot set a nullptr compiled network. ERROR: Cannot set compiled network. ERROR: Runtime loadNetworkFromFile fails. ERROR: Cannot initialize runtime pool. ...Choose hardware engine for framework
tensorflow-lite:Please skip this step for framework
neuronsdk.Execute on CPU:
The process will also run on CPU if no engine is specified.
ENGINE=cpuExecute on GPU through ArmNN delegate:
ENGINE=armnnExecute on MDLA through Stable delegate:
ENGINE=stable_delegate
Run the command:
Online inference on tensorflow-lite
python3 /usr/bin/nnstreamer-demo/run_nnstreamer_example.py --app $APP --cam_type $CAM_TYPE --cam $CAMERA_NODE_ID --framework $FRAMEWORK --engine $ENGINE --performance $MODEOffline inference on neuronsdk
Actually this is as same as the above one but eliminating the
--engineargument.python3 /usr/bin/nnstreamer-demo/run_nnstreamer_example.py --app $APP --cam_type $CAM_TYPE --cam $CAMERA_NODE_ID --framework $FRAMEWORK --performance $MODE
Average inference time
Average inference time of nnstreamer_example_object_detection_yolov5 (UVC) CPU
ARMNN GPU
Neuron Stable
NNAPI(VPU)
NeuronSDK
Genio-350
295
140
Not supported
Not supported
Not supported
Genio-510
55
46.5
5.2
Not supported
5.9
Genio-700
57
37.5
3.6
Not supported
4.9
Genio-1200
41
24.5
27.9
Not supported
Not supported
Pipeline graph
Here is the GStreamer pipeline defined in the example
nnstreamer_example_object_detection_yolov5.pywith--cam uvcand--framework neuronsdk. The pipeline graph is generated through thegst-reportcommand fromgst-instrumentstool. The details can be found in Pipeline Profiling:gst-launch-1.0 \ v4l2src name=src device=/dev/video5 io-mode=mmap num-buffers=300 ! video/x-raw,width=640,height=480,format=YUY2 ! tee name=t_raw \ t_raw. ! queue leaky=2 max-size-buffers=10 ! compositor name=mix sink_0::zorder=1 sink_1::zorder=2 ! fpsdisplaysink sync=false video-sink="waylandsink sync=false fullscreen=0" \ t_raw. ! queue leaky=2 max-size-buffers=2 ! videoconvert ! videoscale ! video/x-raw,width=320,height=320,format=RGB ! tensor_converter ! \ tensor_filter framework=neuronsdk model=/usr/bin/nnstreamer-demo/yolov5s-int8.dla inputtype=uint8 input=3:320:320:1 outputtype=uint8 output=85:6300:1 ! \ other/tensors,num_tensors=1,types=uint8,dimensions=85:6300:1:1,format=static ! \ tensor_transform mode=arithmetic option=typecast:float32,add:-4.0,mul:0.0051498096 ! \ tensor_decoder mode=bounding_boxes option1=yolov5 option2=/usr/bin/nnstreamer-demo/coco.txt option3=0 option4=640:480 option5=320:320 ! queue leaky=2 max-size-buffers=2 ! mix.
Pose Estimation
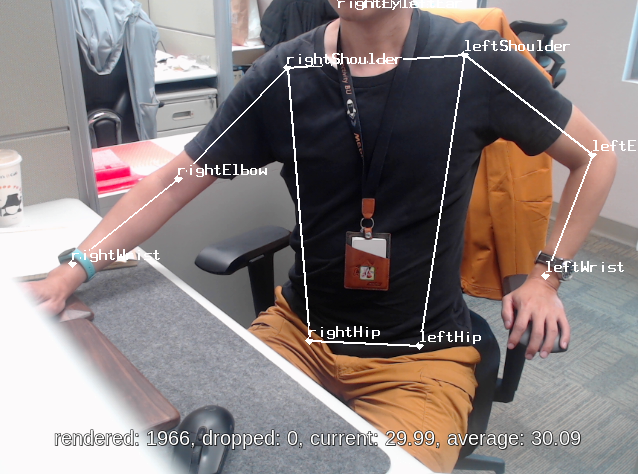
Python script:
/usr/bin/nnstreamer-demo/nnstreamer_example_pose_estimation.pyModel: posenet_mobilenet_v1_100_257x257_multi_kpt_stripped.tflite
Run example:
Set the variable
APPto Pose Estimation application:APP=pose_estimationChoose the framework you like to leverage on:
Online inference on tensorflow-lite
FRAMEWORK=tfliteOffline inference on neuronsdk
FRAMEWORK=neuronsdk
Choose hardware engine for framework
tensorflow-lite:Please skip this step for framework
neuronsdk.Execute on CPU:
The process will also run on CPU if no engine is specified.
ENGINE=cpuExecute on GPU through ArmNN delegate:
ENGINE=armnnExecute on MDLA through Stable delegate:
ENGINE=stable_delegate
Run the command:
Online inference on tensorflow-lite
python3 /usr/bin/nnstreamer-demo/run_nnstreamer_example.py --app $APP --cam_type $CAM_TYPE --cam $CAMERA_NODE_ID --framework $FRAMEWORK --engine $ENGINE --performance $MODEOffline inference on neuronsdk
Actually this is as same as the above one but eliminating the
--engineargument.python3 /usr/bin/nnstreamer-demo/run_nnstreamer_example.py --app $APP --cam_type $CAM_TYPE --cam $CAMERA_NODE_ID --framework $FRAMEWORK --performance $MODE
Average inference time
Average inference time of nnstreamer_example_pose_estimation (UVC) CPU
ARMNN GPU
Neuron Stable
NNAPI(VPU)
NeuronSDK
Genio-350
180
115.3
Not supported
Not supported
Not supported
Genio-510
45
34.5
6.9
Not supported
8.3
Genio-700
50
25
5.2
Not supported
6.5
Genio-1200
42
16.5
5.7
Not supported
6.5
Pipeline graph:
Here is the GStreamer pipeline defined in the example
nnstreamer_example_pose_estimation.pywith--cam uvcand--framework neuronsdk. The pipeline graph is generated through thegst-reportcommand fromgst-instrumentstool. The details can be found in Pipeline Profiling:gst-launch-1.0 \ v4l2src name=src device=/dev/video5 io-mode=mmap num-buffers=300 ! video/x-raw,width=640,height=480,format=YUY2 ! tee name=t_raw \ t_raw. ! queue leaky=2 max-size-buffers=10 ! compositor name=mix sink_0::zorder=1 sink_1::zorder=2 ! fpsdisplaysink sync=false video-sink="waylandsink sync=false fullscreen=0" \ t_raw. ! queue leaky=2 max-size-buffers=2 ! videoconvert ! videoscale ! video/x-raw,width=257,height=257,format=RGB ! tensor_converter ! tensor_transform mode=arithmetic option=typecast:float32,add:-127.5,div:127.5 ! queue ! \ tensor_filter framework=neuronsdk model=/usr/bin/nnstreamer-demo/posenet_mobilenet_v1_100_257x257_multi_kpt_stripped.dla inputtype=float32 input=3:257:257:1 outputtype=float32,float32,float32,float32 output=17:9:9:1,34:9:9:1,32:9:9:1,32:9:9:1 ! queue ! \ tensor_decoder mode=pose_estimation option1=640:480 option2=257:257 option3=/usr/bin/nnstreamer-demo/point_labels.txt option4=heatmap-offset ! queue leaky=2 max-size-buffers=2 ! mix.
Face Detection

Python script:
/usr/bin/nnstreamer-demo/nnstreamer_example_face_detection.pyModel: detect_face.tflite (Download from NNStreamer examples)
Run example:
Set the variable
APPto Face Detection application:APP=face_detectionChoose the framework you like to leverage on:
Online inference on tensorflow-lite
FRAMEWORK=tfliteOffline inference on neuronsdk
FRAMEWORK=neuronsdk
Choose hardware engine for framework
tensorflow-lite:Please skip this step for framework
neuronsdk.Execute on CPU:
The process will also run on CPU if no engine is specified.
ENGINE=cpuExecute on GPU through ArmNN delegate:
ENGINE=armnnExecute on MDLA through Stable delegate:
ENGINE=stable_delegate
Run the command:
Online inference on tensorflow-lite
python3 /usr/bin/nnstreamer-demo/run_nnstreamer_example.py --app $APP --cam_type $CAM_TYPE --cam $CAMERA_NODE_ID --framework $FRAMEWORK --engine $ENGINE --performance $MODEOffline inference on neuronsdk
Actually this is as same as the above one but eliminating the
--engineargument.python3 /usr/bin/nnstreamer-demo/run_nnstreamer_example.py --app $APP --cam_type $CAM_TYPE --cam $CAMERA_NODE_ID --framework $FRAMEWORK --performance $MODE
Average inference time
Average inference time of nnstreamer_example_face_detection (UVC) CPU
ARMNN GPU
Neuron Stable
NNAPI(VPU)
NeuronSDK
Genio-350
237
113.2
Not support
Not support
Not support
Genio-510
83
41.8
11.2
Not support
12.5
Genio-700
60
31
7.8
Not support
9.1
Genio-1200
52
23.4
5.9
Not support
6.8
Pipeline graph:
Here is the GStreamer pipeline defined in the example
nnstreamer_example_face_detection.pywith--cam uvcand--framework neuronsdk. The pipeline graph is generated through thegst-reportcommand fromgst-instrumentstool. The details can be found in Pipeline Profiling:gst-launch-1.0 \ v4l2src name=src device=/dev/video5 io-mode=mmap num-buffers=300 ! video/x-raw,width=640,height=480,format=YUY2 ! tee name=t_raw \ t_raw. ! queue leaky=2 max-size-buffers=10 ! videoconvert ! cairooverlay name=tensor_res ! fpsdisplaysink sync=false video-sink="waylandsink sync=false fullscreen=0" \ t_raw. ! queue leaky=2 max-size-buffers=2 ! videoconvert ! videoscale ! video/x-raw,width=300,height=300,format=RGB ! tensor_converter ! tensor_transform mode=arithmetic option=typecast:float32,add:-127.5,div:127.5 ! \ tensor_filter framework=neuronsdk model=/usr/bin/nnstreamer-demo/detect_face.dla inputtype=float32 input=3:300:300:1 outputtype=float32,float32 output=4:1:1917:1,2:1917:1 ! \ tensor_sink name=res_face
Monocular Depth Estimation

Python script:
/usr/bin/nnstreamer-demo/nnstreamer_example_monocular_depth_estimation.pyModel: midas.tflite
Run example:
Set the variable
APPto Face Detection application:APP=monocular_depth_estimationChoose the framework you like to leverage on:
Online inference on tensorflow-lite
FRAMEWORK=tfliteOffline inference on neuronsdk
FRAMEWORK=neuronsdk
Choose hardware engine for framework
tensorflow-lite:Please skip this step for framework
neuronsdk.Execute on CPU:
The process will also run on CPU if no engine is specified.
ENGINE=cpuExecute on GPU through ArmNN delegate:
ENGINE=armnnExecute on MDLA through Stable delegate:
ENGINE=stable_delegate
Run the command:
Online inference on tensorflow-lite
python3 /usr/bin/nnstreamer-demo/run_nnstreamer_example.py --app $APP --cam_type $CAM_TYPE --cam $CAMERA_NODE_ID --framework $FRAMEWORK --engine $ENGINE --performance $MODEOffline inference on neuronsdk
Actually this is as same as the above one but eliminating the
--engineargument.python3 /usr/bin/nnstreamer-demo/run_nnstreamer_example.py --app $APP --cam_type $CAM_TYPE --cam $CAMERA_NODE_ID --framework $FRAMEWORK --performance $MODE
Average inference time
Average inference time of nnstreamer_example_monocular_depth_estimation (UVC) CPU
ARMNN GPU
Neuron Stable
NNAPI(VPU)
NeuronSDK
Genio-350
701
350
Not supported
1822
Not supported
Genio-510
240
120
22.7
Not supported
23.2
Genio-700
158
87
16.3
Not supported
16.5
Genio-1200
144
62
33.3
Not supported
Not supported
Pipeline graph:
Here is the GStreamer pipeline defined in the example
nnstreamer_example_monocular_depth_estimation.pywith--cam uvcand--framework neuronsdk. The pipeline graph is generated through thegst-reportcommand fromgst-instrumentstool. The details can be found in Pipeline Profiling:gst-launch-1.0 \ v4l2src name=src device=/dev/video5 ! video/x-raw,format=YUY2,width=640,height=480 num-buffers=300 ! videoconvert ! videoscale ! \ video/x-raw,format=RGB,width=256,height=256 ! tensor_converter ! tensor_transform mode=arithmetic option=typecast:float32,add:-127.5,div:127.5 ! \ tensor_filter latency=1 framework=neuronsdk throughput=0 model=/usr/bin/nnstreamer-demo/midas.dla inputtype=float32 input=3:256:256:1 outputtype=float32 output=1:256:256:1 ! \ appsink name=sink emit-signals=True max-buffers=1 drop=True sync=False
Image-Input Application
A Portable Network Graphics(.png) file is required for acting as input source for the following demonstrations.
General Configuration
The examples in this section share some common configurations. It means that users can only change the application option without modifying the shared settings.
The common settings for the input image with enabling the Performance Mode are shown below:
IMAGE_PATH=/usr/bin/nnstreamer-demo/original.png
IMAGE_WIDTH=600
IMAGE_HEIGHT=400
MODE=1
Low Light Image Enhancement

Python script:
/usr/bin/nnstreamer-demo/nnstreamer_example_low_light_image_enhancement.pyModel: lite-model_zero-dce_1.tflite
Run example:
The example image (
/usr/bin/nnstreamer-demo/original.png) was downloaded from paperswithcode:.Set the variable
APPto Low Light Image Enhancement application:APP=low_light_image_enhancementChoose the framework you like to leverage on:
Online inference on tensorflow-lite
FRAMEWORK=tfliteOffline inference on neuronsdk
FRAMEWORK=neuronsdk
Choose hardware engine for framework
tensorflow-lite:Please skip this step for framework
neuronsdk.Execute on CPU:
The process will also run on CPU if no engine is specified.
ENGINE=cpuExecute on MDLA through Stable delegate:
ENGINE=stable_delegate
Run the command:
Online inference on tensorflow-lite
python3 /usr/bin/nnstreamer-demo/run_nnstreamer_example.py --app $APP --img $IMAGE_PATH --width $IMAGE_WIDTH --height $IMAGE_HEIGHT --framework $FRAMEWORK --engine $ENGINE --performance $MODEOffline inference on neuronsdk
Actually this is as same as the above one but eliminating the
--engineargument.python3 /usr/bin/nnstreamer-demo/run_nnstreamer_example.py --app $APP --img $IMAGE_PATH --width $IMAGE_WIDTH --height $IMAGE_HEIGHT --framework $FRAMEWORK --performance $MODE
The light-enhancing image will be saved in the
/usr/bin/nnstreamer-demoand named aslow_light_enhancement_${FRAMEWORK}_${ENGINE}.png. Users can be able to use the option:--exportto name the output image.
Note
You will fail to run
nnstreamer-demo/run_nnstreamer_example.py --app low_light_image_enhancementwith--engine armnnbecause operatorSQUAREis not supported by Arm NN.python3 /usr/bin/nnstreamer-demo/run_nnstreamer_example.py --app low_light_image_enhancement --img $IMAGE_PATH --framework tflite --engine armnn --width $IMAGE_WIDTH --height $IMAGE_HEIGHT --performance $MODE ... INFO: TfLiteArmnnDelegate: Created TfLite ArmNN delegate. ERROR: Operator SQUARE [92] is not supported by armnn_delegate. ...Average inference time
Average inference time of nnstreamer_example_low_light_image_enhancement CPU
ARMNN GPU
Neuron Stable
NNAPI(VPU)
NeuronSDK
Genio-350
3636
Not supported
Not supported
Not supported
Not supported
Genio-510
1215
Not supported
229
Not supported
101
Genio-700
765
Not supported
147
Not supported
74
Genio-1200
644
Not supported
144
Not supported
79
Pipeline graph:
Here is the GStreamer pipeline defined in the example
nnstreamer_example_low_light_image_enhancement.pywith--framework neuronsdk. The pipeline graph is generated through thegst-reportcommand fromgst-instrumentstool. The details can be found in Pipeline Profiling:gst-launch-1.0 \ filesrc location=/usr/bin/nnstreamer-demo/original.png ! pngdec ! videoscale ! videoconvert ! video/x-raw,width=600,height=400,format=RGB ! \ tensor_converter ! tensor_transform mode=arithmetic option=typecast:float32,add:0,div:255.0 ! \ tensor_filter framework=neuronsdk model=/usr/bin/nnstreamer-demo/lite-model_zero-dce_1.dla inputtype=float32 input=3:600:400:1 outputtype=float32 output=3:600:400:1 ! \ tensor_sink name=tensor_sink
Performance
Inference Time - NNStreamer::tensor_filter Invoke Time
The inference time for each example was measured by the property latency provided by tensor_filter.
Here is the source code of property definition:
Turn on performance profiling for the average latency over the recent 10 inferences in microseconds.
Currently, this accepts either 0 (OFF) or 1 (ON). By default, it's set to 0 (OFF).
To enable the latency profiling for each example, users should modify the python script individually
with adding latency=1 to the tensor_filter’s property setting.
Take nnstreamer_example_image_classification.py as example:
Edit python script:
nnstreamer_example_image_classification.py.Search for
tensor_filterand addlatency=1after it.if engine == 'neuronsdk': tensor = dla_converter(self.tflite_model, self.dla) cmd += f'tensor_filter latency=1 framework=neuronsdk model={self.dla} {tensor} ! ' elif engine == 'tflite': cpu_cores = find_cpu_cores() cmd += f'tensor_filter latency=1 framework=tensorflow-lite model={self.tflite_model} custom=NumThreads:{cpu_cores} ! ' elif engine == 'armnn': library = find_armnn_delegate_library() cmd += f'tensor_filter latency=1 framework=tensorflow-lite model={self.tflite_model} custom=Delegate:External,ExtDelegateLib:{library},ExtDelegateKeyVal:backends#GpuAcc ! 'Save the python script.
Enable glib log level to
allto show the debug messages:export G_MESSAGES_DEBUG=allRun the example. You can be able to find the log similar to:
Invoke took 2.537 ms, which is regarded as the inference time.CAM_TYPE=uvc CAMERA_NODE_ID=130 MODE=1 FRAMEWORK=neuronsdk python3 /usr/bin/nnstreamer-demo/run_nnstreamer_example.py --app image_classification --cam_type $CAM_TYPE --cam $CAMERA_NODE_ID --framework $FRAMEWORK --performance $MODE ... ... ** INFO: 03:16:01.589: [/usr/bin/nnstreamer-demo/mobilenet_v1_1.0_224_quant.dla] Invoke took 2.537 ms ... ...
NNStreamer Advanced Pipeline Examples
Pipeline Profiling
IoT Yocto provide gst-instrument as profiling tool for performance analysis and data flow inspection of the GStreamer pipeline.
Here goes two fundamental options:
gst-top-1.0:It will show the performance report for each element in pipeline.
gst-top-1.0 \ gst-launch-1.0 \ v4l2src name=src device=/dev/video5 io-mode=mmap num-buffers=300 ! video/x-raw,width=640,height=480,format=YUY2 ! tee name=t_raw t_raw. ! queue leaky=2 max-size-buffers=10 ! \ ... Got EOS from element "pipeline0". Execution ended after 0:00:10.221403924 Setting pipeline to NULL ... Freeing pipeline ... ELEMENT %CPU %TIME TIME videoconvert0 13.8 55.3 1.41 s videoscale0 3.7 14.9 379 ms tensortransform0 2.2 9.0 228 ms fps-display-text-overlay 2.0 8.1 207 ms tensordecoder0 0.7 2.8 71.9 ms tensorfilter0 0.6 2.3 59.5 ms ...Also save the statistics as a GstTrace file named
gst-top.gsttracels -al *.gsttrace -rw-r--r-- 1 root root 11653120 Jan 4 05:23 gst-top.gsttracegst-report:It will convert GstTrace file to performance graph in DOT format:
gst-report-1.0 --dot gst-top.gsttrace | dot -Tsvg > perf.svgThe performance graph of
nnstreamer_example_object_detection.pyis shown as below. It shows CPU usage, time usage, and execution time among the elements. Users can easily figure out the portion of occupied CPU resource of each element, also of the execution time.In this case, the
tensor_transformconsumed 56.9% of the total execution time because it processes the buffer data conversion with the CPU computation.
Note
Please refer to NNstreamer online document: Profiling for details.