Platform-Aware Model Design Guide
Introduction
This document is for engineers interested in optimizing deep learning models for improved performance on MediaTek Deep Learning Accelerator (MDLA) 1.5, 2.0, and 3.0 devices with the MDLA compiler. The document includes several topics that have the highest impact on runtime performance.
The table below shows the MDLA versions of MediaTek SoCs and MDLA-supported data types:
MDLA version |
int8 capability |
int16 capability |
FP16 capability |
|---|---|---|---|
MDLA 1.5 |
1024 MAC/cycle |
512 MAC/cycle |
256 MAC/cycle |
MDLA 2.0 |
1024 MAC/cycle |
512 MAC/cycle |
512 MAC/cycle |
MDLA 3.0 |
2048 MAC/cycle |
512 MAC/cycle |
512 MAC/cycle |
Data Conversion Overhead
The MDLA only supports FP16. For FP32 models, the MDLA compiler uses the MediaTek DMA engine to convert data types from FP32 to FP16 for each input, and convert FP16 to FP32 for each output. To avoid this data conversion, users can use the –suppress-[input/output]-conversion compiler option to bypass data conversion (including FP32↔FP16 conversion and data re-layout) at [input/output].
To support asymmetric INT8 in MDLA 1.5, the MDLA compiler converts asymmetric INT8 to asymmetric UINT8 for each input, and converts asymmetric UINT8 to asymmetric INT8 for each output. To avoid these overheads on an MDLA 1.5, we suggest using UINT8 rather than INT8 for asymmetric quantization. The data type matrix table is shown below.
HW means native hardware support in MDLA. No extra data conversion overheads.
SW means data conversion is performed by software. We recommend you avoid these data types.
Data Type |
MDLA 1.5 |
MDLA 2.0 |
MDLA 3.0 |
|---|---|---|---|
FP32 ( |
SW |
SW |
SW |
FP16 |
HW |
HW |
HW |
ASYM UINT8 |
HW |
HW |
HW |
ASM INT8 |
SW |
HW |
HW |
SYM INT8 |
HW |
HW |
HW |
SYM INT16 |
HW |
HW |
HW |
Data Layout Optimization
For memory read/write efficiency or hardware constraints, the MDLA may require a special tensor data layout.
The following conditions result in a data re-layout overhead at run time:
A non-constant input tensor uses an incompatible data layout.
An output tensor uses an incompatible data layout.
The following conditions result in a data re-layout overhead at compile time:
A constant input tensor uses an incompatible data layout.
The following conditions result in other data re-layout overheads:
When two operations A and B run on two different devices, for example the MDLA and the VPU, then there may be a runtime data re-layout overhead between A and B if the data layout requirements of the two devices are incompatible.
MDLA Tensor Layouts
The MDLA uses NHWC format for the activation tensors. There are two kinds of data layouts for tensors in external memory (i.e., DRAM and APU TCM):
Data Layout |
Applicable Tensors |
Descriptions |
|---|---|---|
4C |
Tensors with C <= 4 |
|
16C |
Tensors with any C |
|
The data re-layout overhead mostly comes from MDLA input activation. We use the DMA engine to perform data re-layout at runtime, and we suggest you use aligned channel size. For the output activation, the MDLA can efficiently output an NHWC tensor without pitch constraints. The data layout of each tensor is determined by the MDLA compiler, based on the given graph and MDLA constraints.
For example:
Operation A supports 4C and 16C
Operation B only supports 16C
A and B are the inputs of an element-wise op (e.g., ADD) or CONCAT
Element-wise ops (e.g., ADD/MUL) and CONCAT require that all inputs use the same data layout. Therefore, the compiler prefers to use a 16C data layout for the output tensor of operation A to avoid data re-layout from 4C to 16C.
Optimization Hint To reduce data re-layout overheads, models should avoid using an unaligned channel size. Otherwise, use a channel size with a better data re-layout mechanism. |
Optimization Hint Users can use suppressInputConversion and suppressOutputConversion to bypass data re-layout overheads.
|
Op Optimization Hints
This section describes operation optimization based on TensorFlow Lite op definitions.
TFLite Operations
Op Name |
Version |
Available |
Optimization Hint |
|---|---|---|---|
ADD |
1 |
MDLA 1.5 |
|
MDLA 3.0 |
|
||
SUB |
1 |
MDLA 1.5 |
|
MDLA 2.0 |
|
||
MDLA 3.0 |
|
||
MUL |
1 |
MDLA 1.5 |
|
MDLA 3.0 |
|
||
DIV |
1 |
MDLA 1.5 |
None |
MAXIMUM |
1 |
MDLA 1.5 |
Hardware broadcast is not supported except when the smaller input is a constant. The MDLA compiler supports the SW method which needs extra DMA commands. |
MDLA 2.0 |
|
||
MDLA 3.0 |
|
||
MINIMUM |
1 |
MDLA 1.5 |
Hardware broadcast is not supported except when the smaller input is a constant. MDLA compiler supports the SW method which needs extra DMA commands. |
MDLA 2.0 |
|
||
MDLA 3.0 |
|
||
RESIZE_BILINEAR |
1 |
MDLA 1.5 |
Only supports 16C format. |
RESIZE_NEAREST |
1 |
MDLA 1.5 |
Only supports 16C format. |
AVERAGE_POOL_2D |
1 |
MDLA 1.5 |
|
MAX_POOL_2D |
1 |
MDLA 1.5 |
|
L2_POOL_2D |
1 |
MDLA 1.5 |
|
MAX_POOL_3D |
1 |
MDLA 3.0 |
|
CONV_2D |
1 |
MDLA 1.5 |
|
CONV_3D |
1 |
MDLA 3.0 |
Same as CONV_2D. |
RELU |
1 |
MDLA 1.5 |
Please refer to the Math operation throughput table. |
RELU6 |
1 |
MDLA 1.5 |
Please refer to the Math operation throughput table. |
RELU_N1_TO_1 |
1 |
MDLA 1.5 |
Please refer to the Math operation throughput table. |
TANH |
1 |
MDLA 1.5 |
Please refer to the Math operation throughput table. |
LOGISTIC |
1 |
MDLA 1.5 |
Please refer to the Math operation throughput table. |
ELU |
1 |
MDLA 1.5 |
Please refer to the Math operation throughput table. |
DEPTHWISE_CONV_2D |
1, 2 |
MDLA 1.5 |
|
TRANSPOSE_CONV |
1 |
MDLA 1.5 |
Supports 4C/16C format. There are two ways to run transpose convolution on MDLA: HW native support and SW support. SW-supported transpose convolution can be enabled with a compiler option. |
MDLA 3.0 |
|
||
CONCATENATION |
1 |
MDLA 1.5 |
The MDLA compiler optimizes away a concatenation operation if each of the operation’s operands only has one user. |
MDLA 3.0 |
HW native support CONCATENATION, the input tensors can be shared with another op. |
||
FULLY_CONNECTED |
1 |
MDLA 1.5 |
Avoid using FULLY_CONNECTED with \(input\ scale\ \times filter\ scale\ \geq output\text{\ scale}\) or the compiler will insert requant after FULLY_CONNECTED for MDLA 1.5. |
RESHAPE |
1 |
MDLA 1.5 |
None |
SQUEEZE |
1 |
MDLA 1.5 |
None |
EXPAND_DIMS |
1 |
MDLA 1.5 |
None |
PRELU |
1 |
MDLA 1.5 |
Please refer to the Math operation throughput table. |
SLICE |
1 |
MDLA 1.5 |
|
STRIDED_SLICE |
1 |
MDLA 1.5 |
4C: HW only supports strided-slice in W-direction. |
SPLIT |
1, 2, 3 |
MDLA 1.5 |
|
PAD |
1 |
MDLA 1.5 |
Pad can be fused into the following ops if the padding size <= 15 for H and W dimensions.
Otherwise, extra DMA operations are required. |
MDLA 3.0 |
Reflection and Symmetric padding only support NHWC 16C format. |
||
MEAN |
1 |
MDLA 1.5 |
HW only supports 16C. |
TRANSPOSE |
1 |
MDLA 1.5 |
None |
BATCH_TO_SPACE_ND |
1 |
MDLA 1.5 |
None |
SPACE_TO_BATCH_ND |
1 |
MDLA 1.5 |
SPACE_TO_BATCH_ND is supported by pure SW implementation; we suggest not using it frequently in your network. |
SPACE_TO_DEPTH |
1 |
MDLA 1.5 |
SPACE_TO_DEPTH is supported by pure SW implementation; we suggest not using it frequently in your network. |
MDLA 2.0 |
HW supports SPACE_TO_DEPTH. |
||
DEPTH_TO_SPACE |
1 |
MDLA 1.5 |
DEPTH_TO_SPACE is supported by pure SW implementation; we suggest not using it frequently in your network. |
MDLA 2.0 |
HW support DEPTH_TO_SPACE. |
||
NEG |
1 |
MDLA 1.5 |
Please refer to the Math operation throughput table. |
ABS |
1 |
MDLA 1.5 |
Please refer to the Math operation throughput table. |
POW |
1 |
MDLA 1.5 |
Please refer to the Math operation throughput table. |
SQUARED_DIFFERENCE |
1 |
MDLA 1.5 |
SQUARED_DIFFERENCE = (EWE_SUB+EWE_MUL) |
QUANTIZE |
1 |
MDLA 1.5 |
Please refer to section: Quantization support. |
DEQUANTIZE |
1 |
MDLA 1.5 |
Please refer to section: Quantization support. |
Quantized LSTM (5 inputs) |
1, 2 |
MDLA 1.5 |
None |
EXP |
1 |
MDLA 2.0 |
Please refer to the Math operation throughput table. |
SQUARE |
1 |
MDLA 2.0 |
Please refer to the Math operation throughput table. |
SQRT |
1 |
MDLA 2.0 |
Please refer to the Math operation throughput table. |
RSQRT |
1 |
MDLA 2.0 |
Please refer to the Math operation throughput table. |
RCP |
1 |
MDLA 2.0 |
Please refer to the Math operation throughput table. |
SOFTMAX |
1 |
MDLA 2.0 |
None |
MediaTek Custom Operations in TFLite
Some frequently-used TensorFlow operations do not exist in TFLite, for example: crop_and_resize. Our Tensorflow-to-TFLite converter provides MTK custom ops for customer use.
Op Name |
Version |
Available |
Optimization hint |
|---|---|---|---|
MTK_ABS |
1 |
MDLA 1.5 |
None |
MTK_MIN_POOL |
1 |
MDLA 1.5 |
|
MTK_TRANSPOSE_CONV |
1 |
MDLA 1.5 |
|
MTK_REVERSE |
1 |
MDLA 1.5 |
None |
MTK_ELU |
1 |
MDLA 1.5 |
None |
MTK_REQUANTIZE |
1 |
MDLA 1.5 |
Please refer to section: Quantization support |
MTK_DEPTH_TO_SPACE |
1 |
MDLA 1.5 |
DEPTH_TO_SPACE is supported by pure SW implementation; we suggest not using it frequently in your network. |
MTK_CROP_AND_RESIZE |
1 |
MDLA 1.5 |
None |
MTK_LAYER_NORMALIZATION |
2 |
MDLA 2.0 |
None |
MDLA Convolution Rate
This section describes Convolution uRate. Note that we assume BW is not considered, and the tensor is 4C/16C format.
Mode |
uRate |
Note |
|
|---|---|---|---|
CONV_2D |
100% |
Stride and filter size doesn’t affect the uRate except with the following small filter cases: MDLA 1.5 & 2.0:
MDLA 3.0:
The uRate will be lower. |
|
DEPTHWISE_CONV_2D |
25% |
Stride and filter size doesn’t affect the uRate except with the following small filter cases: MDLA 1.5 & 2.0:
MDLA 3.0:
The uRate will be lower. |
|
FULLY_CONNECTED Batch=1 |
12.5% |
MDLA 1.5/2.0: 25% MDLA 3.0: 12.5% |
|
FULLY_CONNECTED Batch=2 |
25% |
MDLA 1.5/2.0: 50% MDLA 3.0: 25% |
|
FULLY_CONNECTED Batch=4 |
50% |
MDLA 1.5/2.0: 100% MDLA 3.0: 50% |
|
FULLY_CONNECTED Batch=8 |
100% |
MDLA 1.5/2.0: 100% MDLA 3.0: 100% |
|
TRANSPOSE_CONV (HW Solution) |
100% |
MDLA 1.5 & 2.0 only:
|
|
MTK_TRANSPOSE_CONV (SW Solution) |
~100% |
MAC uRate is nearly 100%, but have activation reload overhead. |
MDLA Op Throughput
This section describes operation throughput based on hardware capability.
Math Operation Throughput (Pixel/Cycle)
Op Name |
Available |
Sym8 |
Asym8 |
Sym16 |
FP16 |
|---|---|---|---|---|---|
RELU |
MDLA 1.5 |
32 |
32 |
16 |
16 |
RELU6 |
MDLA 1.5 |
32 |
32 |
16 |
16 |
RELU_N1_TO_1 |
MDLA 1.5 |
32 |
32 |
16 |
16 |
TANH |
MDLA 1.5 |
4 |
4 |
4 |
4 |
MDLA 2.0 |
16 |
16 |
4 |
8 |
|
LOGISTIC |
MDLA 1.5 |
4 |
4 |
4 |
4 |
MDLA 2.0 |
16 |
16 |
4 |
8 |
|
ELU |
MDLA 1.5 |
4 |
4 |
4 |
4 |
MDLA 2.0 |
16 |
16 |
4 |
8 |
|
GELU |
MDLA 2.0 |
16 |
16 |
4 |
8 |
EXP |
MDLA 2.0 |
16 |
16 |
4 |
8 |
RCP |
MDLA 2.0 |
16 |
16 |
4 |
8 |
SQRT |
MDLA 2.0 |
16 |
16 |
4 |
8 |
PRELU |
MDLA 1.5 |
16 |
16 |
16 |
8 |
MAX |
MDLA 1.5 |
16 |
16 |
8 |
8 |
MIN |
MDLA 1.5 |
16 |
16 |
8 |
8 |
BN_MUL |
MDLA 1.5 |
16 |
16 |
16 |
8 |
SQUARE(MUL) |
MDLA 2.0 |
16 |
16 |
16 |
8 |
MUL |
MDLA 1.5 |
16 |
16 |
8 |
8 |
BN_ADD |
MDLA 1.5 |
16 |
16 |
16 |
8 |
IN_SUB |
MDLA 2.0 |
16 |
16 |
16 |
8 |
ADD |
MDLA 1.5 |
8 |
8 |
8 |
8 |
MDLA 3.0 |
16 |
16 |
8 |
8 |
|
SUB |
MDLA 1.5 |
8 |
8 |
8 |
8 |
MDLA 3.0 |
16 |
16 |
8 |
8 |
|
NEG |
MDLA 1.5 |
16 |
16 |
16 |
16 |
ABS |
MDLA 1.5 |
16 |
16 |
16 |
16 |
MDLA Pool Operation Throughput
Op Name |
Sym8 |
Asym8 |
Sym16 |
FP16 |
|---|---|---|---|---|
AVG |
TP |
TP |
TP/2 |
TP/2 |
L2 |
TP |
TP |
TP/2 |
NA |
MAX |
TP |
TP |
TP/2 |
TP/2 |
MIN |
TP |
TP |
TP/2 |
TP/2 |
Note:
TP(Throughput) = 1/TC (unit: tile per cycle)
TC(Total Cycles per tile) =(ps_w*ps_h + (tile_W-1)*ps_h*s_w)*((tile_H-ps_h)/s_h+1)*(tile_C/16)
tile_H/W/C: output tile dimensions of POOL
ps_w: pool size in W
ps_h: pool size in H
s_w: stride size in W
s_h: stride size in H
MDLA BLE RESIZE Operation Throughput
Scaling up:
SYM8/ASYM8: 10points / cycle
SYM16/FP16: 5points / cycle
Scaling down:
Performance is not as good as scaling up. We strongly suggest replacing BLE RESIZE scaling down with stride CONV_2D.
MDLA Fusion Rules
This section lists the operation fusion support for each MDLA version. Note that the MDLA compiler will fuse multiple operations if it is beneficial.
Group |
Ops |
|---|---|
CONV |
Conv2D Depthwise Conv2D Fully Connected Transpose Conv2D |
MATH1 |
Batch normalization (TFLite converter will fold BN into Conv2D) Abs Neg |
MATH2 |
Mul Add Sub Max Min |
ACT1 |
ReLU Tanh Sigmoid |
ACT2 |
PReLU |
POOL |
AVG Pool Max Pool Min Pool L2 Pool |
RESIZE |
Resize bilinear Resize nearest |
DEQUANTIZE |
Dequantize |
REQUANT |
Requant |
MDLA version |
Fusion rule |
|---|---|
MDLA 1.5 |
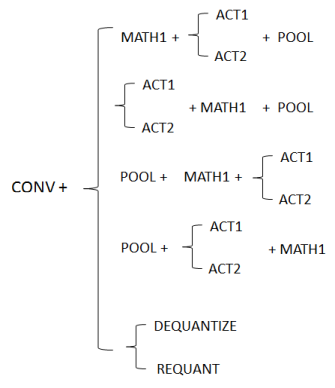
Rule A: Op sequence starts with CONV Op sequences can still be fused even without an exact match; some operations could be skipped. For example: CONV + MATH1, CONV + ACT1/ACT2, CONV + POOL is also supported.
|
Rule B: Op sequence starts without CONV
|
|
MDLA hardware also supports Conv2D+Conv2D or Depthwise Conv2D+Conv2D fusion. Fusion of more than two CONV ops is not supported. Rule C: Group 1(Rule A/B) + Group 2(Rule A) Restriction:
The output tensors of Group 1 must be used by Group 2 only, i.e. fusion of multiple use is not supported. |
|
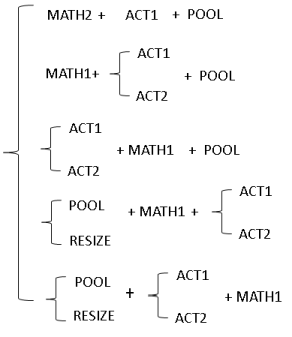
MDLA 2.0 |
Rule A-C supported. Rule D: Op sequence starts with CONV
|
Rule E: Op sequence starts with CONV
|
|
MDLA 3.0 |
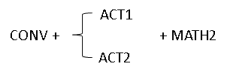
Rule F: CONV + RESIZE + MATH1/ACT1/ACT2 MDLA 3.0 DLF (Deep Layer Fusion) supports operation fusion without the layer number limitation which qualified the above fusion rules.
DLF can save lots of external bandwidth and power by replacing external bandwidth with internal data flow. DLF constraints:
|
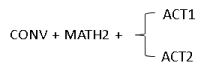
Device Switch Overhead
MDLA compiler supports heterogeneous compilation and partitioning of the graph by device capabilities.
We define device switch overhead from A to B as the execution endpoint of device A to the execution start point of device B.

Figure 8-1. Device switch overhead
Pre-processing input/output: Perform memory copy for temporary buffers if A and B’s device memory domains are different. For example, MDLA and DSP share the same memory domain so there is no memory copy overhead.
Prepare for device execution: The initialization time of the device driver.
Device execution: Hardware IP runtime. Note that the data re-layout overhead is included in this time.
By passing –show-exec-plan to ncc-tflite, you will see how the compiler partition the network and device plan. To minimize the device switch overhead, we suggest you modify your network to run entirely on the MDLA if possible.
Data synchronization overhead The MDLA compiler and runtime manipulate MDLA and DSP device memory using dma-buf. The cache invalidation and flush process will occur when control passes from the CPU to the APU, and from the APU to the CPU. This overhead is typically quite small (<1ms) and transparent to the user. |
Optimization Hint: Hardware buffer Users can use dma-buf buffer for inputs and outputs in order to eliminate unnecessary data copying. Both the MDLA and DSP can directly access the ION buffer. |
Runtime Support Features
Users should avoid using features that require runtime support if possible. The following features have runtime overheads:
Dynamic Shape
Unlike the CPU, the MDLA requires that the shape of each tensor should be known and fixed at compile time. This also allows better optimizations (e.g., tiling) and memory management. To handle models with dynamic shapes, the MDLA compiler must patch MDLA instructions and re-allocate memory at runtime.
Control Flow
Control flow operations (e.g., IF and WHILE) are not currently natively supported by the MDLA. All control flow operations are handled by the MDLA runtime.
Quantization Support
Quantization refers to techniques for performing both computation and memory access with lower precision data. This enables performance gains in several important areas:
Model size
Memory bandwidth
Inference time (due to savings in memory bandwidth and faster computing with integer arithmetic)
In addition to per-layer (per-tensor) quantization, MDLA version 1.5 and later also support per-channel quantization and mixed precision quantization (8-bit/16-bit).
Per-Channel Quantization
For per-channel quantization, the following data types of input and weight can be supported by MDLA version 1.5 and later.
Input |
||||
|---|---|---|---|---|
ASYM UINT8 |
SYM INT8 |
SYM INT16 |
||
Weight |
ASYM UINT8 |
V |
V |
X |
SYM INT8 |
V |
V |
X (MDLA 1.5/2.0)/ V (MDLA3.0) |
|
SYM INT16 |
X |
X |
V |
Mixed Precision Quantization (8/16-Bit)
To improve accuracy, users can mix 8-bit and 16-bit quantization as well as FP16 in a model. For example, users can use 16-bit quantization (or FP16) for accuracy-sensitive operations and use 8-bit quantization for operations that are not sensitive to accuracy.
The compiler will perform the following steps to support quantization operations:
MTK_REQUANTIZE (integer → integer)
Try to fuse with the preceding single-use CONV_2D or FULLY_CONNECTED if the op exists.
Try to fuse with the preceding single-use ABS, NEG, MIN or MAX if the op exists .
There is no candidate predecessor that MTK_REQUANTIZE can fuse with.
Map to a BN_ADD, if input and output are the same width.
Map to a CONV_2D, if input and output width is different. # The CONV_2D with a filter with shape <c, 1, 1, c>.
QUANTIZE (floating-point→ integer)
Try to fuse with the preceding single-use CONV_2D or FULLY_CONNECTED if the op exists.
There is no candidate predecessor that QUANTIZE can fuse with.
Map to a CONV_2D with a filter with shape <c, 1, 1, c>.
DEQUANTIZE (integer → floating-point)
Check if there is a preceding single-use CONV_2D or FULLY_CONNECTED for fusion.
There is no candidate predecessor that DEQUANTIZE can fuse with.
Create a CONV_2D with a filter with shape <c, 1, 1, c>.
Fuse the CONV_2D or FULLY_CONNECTED with DEQUANTIZE together.
Optimization Guide To reduce the overhead:
Note that the preceded layer should have only one use, otherwise compiler cannot merge or fuse the layer. All CONV_2D created by the compiler should have a filter with shape <c, 1, 1, c>. The bandwidth consumption is related to the channel size. |
Hybrid Quantization
Hybrid quantization stands for convolution-like operations that have float input with quantized weight. This could reduce model size significantly without losing accuracy. However, this kind of quantization is not natively supported by the MDLA 1.5. Operations with hybrid quantization will be executed using float16 type with dequantized weights