Neuron RunTime API V1
To use Neuron Runtime API Version 1 (V1) in an application, include header RuntimeAPI.h. For a full list of Neuron Runtime API V1 functions, Neuron API Reference.
This section describes the typical workflow and has C++ examples of API usage.
Development Flow
The sequence of API calls to accomplish a synchronous inference request is as follows:
Call
NeuronRuntime_createto create a Neuron Runtime instance.Call
NeuronRuntime_loadNetworkFromFileorNeuronRuntime_loadNetworkFromBufferto load a DLA (compiled network).Set the input buffers by calling
NeuronRuntime_setInputin order.Set the first input using
NeuronRuntime_setInput(runtime, 0, static_cast<void *>(buf0), buf0_size_in_bytes, {-1})Set the second input using
NeuronRuntime_setInput(runtime, 1, static_cast<void *>(buf1), buf1_size_in_bytes, {-1})Set the third input using
NeuronRuntime_setInput(runtime, 2, static_cast<void *>(buf1), buf1_size_in_bytes, {-1})… and so on.
Set the model outputs by calling
NeuronRuntime_setOutputin a similar way to setting inputs.Call
NeuronRuntime_setQoSOption(runtime, qos)to configure the QoS options.Call
NeuronRuntime_inference(runtime)to issue the inference request.Call
NeuronRuntime_releaseto release the runtime resource.
QoS Tuning Flow (Optional)
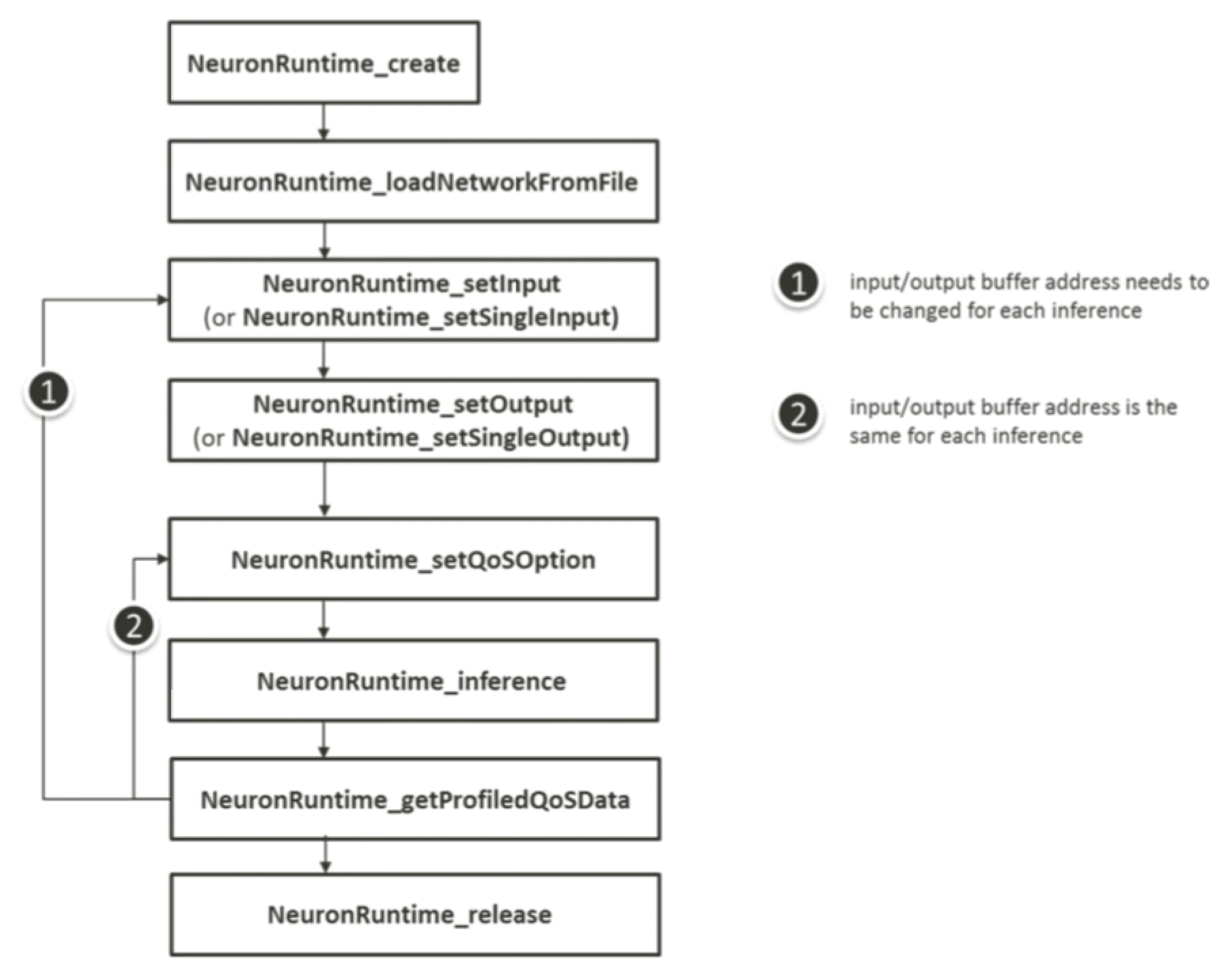
A typical QoS tuning flow consists of two sub-flows, namely, 1) iterative performance/power tuning, and 2) inference using the tuned QoS parameters. Both these flows are further explained in terms of the steps involved.
Iterative Performance/Power Tuning
Use
NeuronRuntime_createto create a Neuron Runtime instance.Load a compiled network using one of the following functions:
Use
NeuronRuntime_loadNetworkFromFileto load a compiled network from a DLA file.Use
NeuronRuntime_loadNetworkFromBufferto load a compiled network from a memory buffer. UsingNeuronRuntime_loadNetworkFromFilealso sets up the structure of the QoS according to the shape of the compiled network.
Use
NeuronRuntime_setInputto set the input buffer for the model. Or useNeuronRuntime_setSingleInputto set the input if the model has only one input.Use
NeuronRuntime_setOutputto set the output buffer for the model. Or useNeuronRuntime_setSingleOutputto set the output if the model has only one output.Prepare
QoSOptionsfor inference:Set
QoSOptions.preferencetoNEURONRUNTIME_PREFER_PERFORMANCEorNEURONRUNTIME_PREFER_POWER.Set
QoSOptions.prioritytoNEURONRUNTIME_PRIORITY_LOW,NEURONRUNTIME_PRIORITY_MED, orNEURONRUNTIME_PRIORITY_HIGH.Set
QoSOptions.abortTimeandQoSOptions.deadlinefor configuring abort time and deadline.Note
A non-zero value in
QoSOptions.abortTimeimplies that this inference will be aborted even if the inference is not completed yet.A non-zero value in
QoSOptions.deadlineimplies that this inference will be scheduled as a real-time task.Both values can be set to zero if there is no requirement on deadline or abort time.
If the profiled QoS data is not presented,
QoSOptions.profiledQoSDatashould benullptr.QoSOptions.profiledQoSDatawill then be allocated in step 8 by invokingNeuronRuntime_getProfiledQoSData.Set
QoSOptions.boostValueto an initial value between 0 (lowest frequency) and 100 (highest frequency). This value is viewed as a hint for the underlying scheduler, and the execution boost value (actual boost value during execution) might be altered accordingly.
Use
NeuronRuntime_setQoSOptionto configure the QoS settings for inference.Use
NeuronRuntime_inferenceto perform the inference.Use
NeuronRuntime_getProfiledQoSDatato check the inference time and execution boost value.If the inference time is too short, users should update
QoSOptions.boostValueto a value less thanexecBootValue(executing boost value) and then repeat step 5.If the inference time is too long, users should update
QoSOptions.boostValueto a value greater thanexecBootValue(executing boost value) and then repeat step 5.If the inference time is good, the tuning process of
QoSOptions.profiledQoSDatais complete.
Note
The
profiledQoSDataallocated byNeuronRuntime_getProfiledQoSDatais destroyed after callingNeuronRuntime_release. The caller should store the contents ofQoSOptions.profiledQoSDatafor later inferences.Use
NeuronRuntime_releaseto release the runtime resource.
Inference Using the Tuned QoSOptions.profiledQoSData
Use
NeuronRuntime_createto create a Neuron Runtime instance.Load a compiled network using one of the following functions:
Use
NeuronRuntime_loadNetworkFromFileto load a compiled network from a DLA file.Use
NeuronRuntime_loadNetworkFromBufferto load a compiled network from a memory buffer. UsingNeuronRuntime_loadNetworkFromFilealso sets up the structure of the QoS according to the shape of the compiled network.
Use
NeuronRuntime_setInputto set the input buffer for the model. Or useNeuronRuntime_setSingleInputto set the input if the model has only one input.Use
NeuronRuntime_setOutputto set the output buffer for the model. Or useNeuronRuntime_setSingleOutputto set the output if the model has only one output.Prepare
QoSOptionsfor inference:Set
QoSOptions.preferencetoNEURONRUNTIME_PREFER_PERFORMANCEorNEURONRUNTIME_PREFER_POWER.Set
QoSOptions.prioritytoNEURONRUNTIME_PRIORITY_LOW,NEURONRUNTIME_PRIORITY_MED, orNEURONRUNTIME_PRIORITY_HIGH.Set
QoSOptions.abortTimeandQoSOptions.deadlinefor configuring abort time and deadline.Note
A non-zero value in
QoSOptions.abortTimeimplies that this inference will be aborted even if the inference is not completed yet.A non-zero value in
QoSOptions.deadlineimplies that this inference will be scheduled as a real-time task.Both values can be set to zero if there is no requirement on deadline or abort time.
Allocate
QoSOptions.profiledQoSDataand fill its contents with the previously tuned values.Set
QoSOptions.boostValuetoNEURONRUNTIME_BOOSTVALUE_PROFILED.
Use
NeuronRuntime_setQoSOptionto configure the QoS settings for inference.Users must check the return value. A return value of
NEURONRUNTIME_BAD_DATAmeans the structure of the QoS data built in step 2 is not compatible withQoSOptions.profiledQoSData. The inputprofiledQoSDatamust be regenerated with the new version of the compiled network.Use
NeuronRuntime_inferenceto perform the inference.(Optional) Perform inference again. If all settings are the same, repeat step 3 to step 7.
Use
NeuronRuntime_releaseto release the runtime resource.
QoS Extension API (Optional)
QoS Extension allows the user to set the behavior of the system (e.g. CPU, memory) during network inference.
The user sets the behavior by specifying a pre-configured performance preference. For detailed documentation on the API, see Neuron API Reference
Performance Preferences
Preference Name |
Note |
|---|---|
NEURONRUNTIME_PREFERENCE_BURST |
Prefer performance. |
NEURONRUNTIME_PREFERENCE_HIGH_PERFORMANCE |
|
NEURONRUNTIME_PREFERENCE_PERFORMANCE |
|
NEURONRUNTIME_PREFERENCE_SUSTAINED_HIGH_PERFORMANCE |
Prefer balance. |
NEURONRUNTIME_PREFERENCE_SUSTAINED_PERFORMANCE |
|
NEURONRUNTIME_PREFERENCE_HIGH_POWER_SAVE |
|
NEURONRUNTIME_PREFERENCE_POWER_SAVE |
Prefer low power. |
Development Flow with QoS Extension API
Call
NeuronRuntime_create()to create a Neuron Runtime instance.Call
QoSExtension_acquirePerformanceLock(hdl, preference, qos)to set the performance preference and fetch preset APU QoS options.Set
hdlto -1 for the initial request.Set
preferenceto your performance preference.Set
qosto a QoSOptions object. The system fills this object with a set of pre-configured APU QoS options, determined by the performance preference.
Call
NeuronRuntime_setQoSOption(runtime, qos)using the QoSOptions returned byQoSExtension_acquirePerformanceLockto configure the APU.Set input buffers by calling
NeuronRuntime_setInputin order.Set the first input using
NeuronRuntime_setInput(runtime, 0, static_cast<void *>(buf0), buf0_size_in_bytes, {-1})Set the second input using
NeuronRuntime_setInput(runtime, 1, static_cast<void *>(buf1), buf1_size_in_bytes, {-1})Set the third input using
NeuronRuntime_setInput(runtime, 2, static_cast<void *>(buf1), buf1_size_in_bytes, {-1})… and so on.
Set the model outputs by calling
NeuronRuntime_setOutputin a similar way to setting inputs.Call
NeuronRuntime_inference(runtime)to issue the inference request.Call
QoSExtension_releasePerformanceLockto release the system performance request.Call
NeuronRuntime_releaseto release the runtime resource.
Runtime Options
Call NeuronRuntime_create_with_options to create a Neuron Runtime instance with user-specified options.
Option Name |
Description |
|---|---|
–disable-sync-input |
Disable input sync in Neuron. |
–disable-invalidate-output |
Disable output invalidation in Neuron. |
For example:
// Create Neuron Runtime instance with options
int error = NeuronRuntime_create_with_options("--disable-sync-input --disable-invalidate-output", optionsToDeprecate, runtime)
Suppress I/O Mode (Optional)
Suppress I/O mode is a special mode that eliminates MDLA pre-processing and post-processing time. The user must lay out the inputs and outputs to the MDLA hardware shape (network shape is unchanged) during inference. To do this, follow these steps:
Compile the network with
--suppress-inputor/and--suppress-outputoption to enable suppress I/O Mode.Pass the input ION descriptors to
NeuronRuntime_setInputorNeuronRuntime_setOutput.Call
NeuronRuntime_getInputPaddedSizeto get the aligned data size, and use this value as the buffer size forNeuronRuntime_setInput.Call
NeuronRuntime_getOutputPaddedSizeto get the aligned data size, and use this value as the buffer size forNeuronRuntime_setOutput.Align each dimension of the input data to the hardware-required size. There are no changes in network shape. The hardware-required size of each dimension, in pixels, can be found in *dims. *dims is returned by
NeuronRuntime_getInputPaddedDimensions(void* runtime, uint64_t handle, RuntimeAPIDimensions* dims).Align each dimension of the output data to the hardware-required size. The hardware-required size of each dimension, in pixels, can be found in *dims. *dims is returned by
NeuronRuntime_getOutputPaddedDimensions (void* runtime, uint64_t handle, RuntimeAPIDimensions* dims).
Example code to use this API:
// Get the aligned sizes of each dimension.
RuntimeAPIDimensions dims;
int err_code = NeuronRuntime_getInputPaddedDimensions(runtime, handle, &dims);
// Hardware-aligned sizes of each dimension in pixels.
uint32_t alignedN = dims.dimensions[RuntimeAPIDimIndex::N];
uint32_t alignedH = dims.dimensions[RuntimeAPIDimIndex::H];
uint32_t alignedW = dims.dimensions[RuntimeAPIDimIndex::W];
uint32_t alignedC = dims.dimensions[RuntimeAPIDimIndex::C];
Example: Using Runtime API V1
A sample C++ program is given below to illustrate the usage of the Neuron Runtime APIs and user flows.
#include <iostream>
#include <dlfcn.h>
#include "RuntimeAPI.h"
#include "Types.h"
void * load_func(void * handle, const char * func_name) {
/* Load the function specified by func_name, and exit if the loading is failed. */
void * func_ptr = dlsym(handle, func_name);
if (func_name == nullptr) {
std::cerr << "Find " << func_name << " function failed." << std::endl;
exit(2);
}
return func_ptr;
}
int main(int argc, char * argv[]) {
void * handle;
void * runtime;
// typedef to the functions pointer signatures.
typedef int (*NeuronRuntime_create)(const EnvOptions* options, void** runtime);
typedef int (*NeuronRuntime_loadNetworkFromFile)(void* runtime, const char* dlaFile);
typedef int (*NeuronRuntime_setInput)(void* runtime, uint64_t handle, const void* buffer,
size_t length, BufferAttribute attr);
typedef int (*NeuronRuntime_setOutput)(void* runtime, uint64_t handle, void* buffer,
size_t length, BufferAttribute attr);
typedef int (*NeuronRuntime_inference)(void* runtime);
typedef void (*NeuronRuntime_release)(void* runtime);
typedef int (*NeuronRuntime_getInputSize)(void* runtime, uint64_t handle, size_t* size);
typedef int (*NeuronRuntime_getOutputSize)(void* runtime, uint64_t handle, size_t* size);
// Prepare a memory buffer as input.
unsigned char * buf = new unsigned char[299 * 299 * 3];
for (size_t i = 0; i < 299; ++i) {
for (size_t j = 0; j < 299; ++j) {
buf[i * 299 + j + 0] = 0;
buf[i * 299 + j + 1] = 1;
buf[i * 299 + j + 2] = 2;
}
}
// Open the share library
handle = dlopen("./libneuron_runtime.so", RTLD_LAZY);
if (handle == nullptr) {
std::cerr << "Failed to open libneuron_runtime.so." << std::endl;
exit(1);
}
// Setup the environment options for the Neuron Runtime
EnvOptions envOptions = {
.deviceKind = 0,
.MDLACoreOption = Single,
.CPUThreadNum = 1,
.suppressInputConversion = false,
.suppressOutputConversion = false,
};
// Declare function pointer to each function,
// and load the function address into function pointer
#define LOAD_FUNCTIONS(FUNC_NAME, VARIABLE_NAME) \
FUNC_NAME VARIABLE_NAME = reinterpret_cast<FUNC_NAME>(load_func(handle, #FUNC_NAME));
LOAD_FUNCTIONS(NeuronRuntime_create, rt_create)
LOAD_FUNCTIONS(NeuronRuntime_loadNetworkFromFile, loadNetworkFromFile)
LOAD_FUNCTIONS(NeuronRuntime_setInput, setInput)
LOAD_FUNCTIONS(NeuronRuntime_setOutput, setOutput)
LOAD_FUNCTIONS(NeuronRuntime_inference, inference)
LOAD_FUNCTIONS(NeuronRuntime_release, release)
LOAD_FUNCTIONS(NeuronRuntime_getInputSize, getInputSize)
LOAD_FUNCTIONS(NeuronRuntime_getOutputSize, getOutputSize)
#undef LOAD_FUNCTIONS
// Step 1. Create Neuron Runtime environment
// Parameters:
// envOptions - The environment options for the Neuron Runtime
// runtime - Neuron runtime environment
//
// Return value
// A RuntimeAPI error code
//
int err_code = (*rt_create)(&envOptions, &runtime);
if (err_code != NEURONRUNTIME_NO_ERROR) {
std::cerr << "Failed to create Neuron runtime." << std::endl;
exit(3);
}
// Step 2. Load the compiled network(*.dla) from file
// Parameters:
// runtime - The address of the runtime instance created by NeuronRuntime_create
// pathToDlaFile - The DLA file path
//
// Return value
// A RuntimeAPI error code. 0 indicating load network successfully.
//
err_code = (*loadNetworkFromFile)(runtime, argv[1]);
if (err_code != NEURONRUNTIME_NO_ERROR) {
std::cerr << "Failed to load network from file." << std::endl;
exit(3);
}
// (Options) Check the required input buffer size
// Parameters:
// runtime - The address of the runtime instance created by NeuronRuntime_create
// handle - The frontend IO index
// size - The returned input buffer size
//
// Return value
// A RuntimeAPI error code
//
size_t required_size;
err_code = (*getInputSize)(runtime, 0, &required_size);
if (err_code != NEURONRUNTIME_NO_ERROR) {
std::cerr << "Failed to get single input size for network." << std::endl;
exit(3);
}
std::cout << "The required size of the input buffer is " << required_size << std::endl;
// Step 3. Set the input buffer with our memory buffer (pixels inside)
// Parameters:
// runtime - The address of the runtime instance created by NeuronRuntime_create
// handle - The frontend IO index
// buffer - The input buffer address
// length - The input buffer size
// attribute The buffer attribute for setting ION
//
// Return value
// A RuntimeAPI error code
//
err_code = (*setInput)(runtime, 0, static_cast<void *>(buf), 3 * 299 * 299, {-1});
if (err_code != NEURONRUNTIME_NO_ERROR) {
std::cerr << "Failed to set single input for network." << std::endl;
exit(3);
}
// (Options) Check the required output buffer size
// Parameters:
// runtime - The address of the runtime instance created by NeuronRuntime_create
// handle - The frontend IO index
// size - The returned output buffer size
//
// Return value
// A RuntimeAPI error code
//
err_code = (*getOutputSize)(runtime, 0, &required_size);
if (err_code != NEURONRUNTIME_NO_ERROR) {
std::cerr << "Failed to get single output size for network." << std::endl;
exit(3);
}
std::cout << "The required size of the output buffer is " << required_size << std::endl;
// Step 4. Set the output buffer
// Parameters:
// runtime - The address of the runtime instance created by NeuronRuntime_create
// handle - The frontend IO index
// buffer - The output buffer
// length - The output buffer size
// attribute - The buffer attribute for setting IO
//
// Return value
// A RuntimeAPI error code
//
unsigned char * out_buf = new unsigned char[1001];
err_code = (*setOutput)(runtime, 0, static_cast<void *>(out_buf), 1001, {-1});
if (err_code != NEURONRUNTIME_NO_ERROR) {
std::cerr << "Failed to set single output for network." << std::endl;
exit(3);
}
// Step 5. Do the inference with Neuron Runtime
// Parameters:
// runtime - The address of the runtime instance created by NeuronRuntime_create
//
// Return value
// A RuntimeAPI error code
//
err_code = (*inference)(runtime);
if (err_code != NEURONRUNTIME_NO_ERROR) {
std::cerr << "Failed to inference the input." << std::endl;
exit(3);
}
// Step 6. Release the runtime resource
// Parameters:
// runtime - The address of the runtime instance created by NeuronRuntime_create
//
// Return value
// A RuntimeAPI error code
//
(*release)(runtime);
// Dump all output data.
std::cout << "Output data: " << out_buf[0];
for (size_t i = 1; i < 1001; ++i) {
std::cout << " " << out_buf[i];
}
std::cout << std::endl;
return 0;
}