ONNX Runtime
Introduction
ONNX Runtime is a high-performance, cross-platform engine for scoring and training machine learning models in the ONNX (Open Neural Network Exchange) format. It accelerates inference and training for models from popular frameworks such as PyTorch, TensorFlow/Keras, and classical libraries like scikit-learn, LightGBM, and XGBoost. ONNX Runtime is compatible with various hardware, drivers, and operating systems, leveraging hardware accelerators and advanced graph optimizations for optimal performance.
ONNX Runtime on Genio
ONNX models can be executed efficiently on Genio platforms using ONNX Runtime. We currently support ONNX Runtime v1.20.2 on both Kirkstone and Scarthgap Yocto versions. The ONNX Runtime recipes are included in the meta-mediatek-experimental layer.
To build ONNX Runtime packages as part of your Rity build, follow these steps:
Initialize the repo:
repo init -u https://gitlab.com/mediatek/aiot/bsp/manifest.git -b rity/kirkstone -m mtk-experimental.xml repo init -u https://gitlab.com/mediatek/aiot/bsp/manifest.git -b rity/scarthgap -m mtk-experimental.xml
Sync the repo:
repo sync -j 48
Add the
meta-mediatek-experimentallayer to yourbblayers.conf.Add the following to your
local.conf:" onnxruntime onnxruntime-examples onnxruntime-staticdev "If using Kirkstone, ensure you add:
PREFERRED_VERSION_cmake = "3.26.4"
Build your Rity image as usual:
bitbake rity-demo-image
Executing ONNX Models on Genio
With ONNX Runtime support on Genio, executing ONNX models is straightforward. Below is a sample Python script to benchmark your ONNX models on CPU:
import onnxruntime as ort
import numpy as np
import time
def load_model(model_path):
"""Load the ONNX model."""
session_options = ort.SessionOptions()
session_options.intra_op_num_threads = 4
session_options.execution_mode = ort.ExecutionMode.ORT_SEQUENTIAL
session_options.graph_optimization_level = ort.GraphOptimizationLevel.ORT_ENABLE_ALL
execution_providers = ['XnnpackExecutionProvider', 'CPUExecutionProvider']
session = ort.InferenceSession(model_path, sess_options=session_options, providers=execution_providers)
return session
def generate_sample_input(session):
"""Generate a sample input based on the model's input shape."""
input_name = session.get_inputs()[0].name
input_shape = session.get_inputs()[0].shape
sample_input = np.random.random(input_shape).astype(np.float32)
return {input_name: sample_input}
def run_inference(session, input_data):
"""Run inference and measure time taken."""
start_time = time.time()
outputs = session.run(None, input_data)
end_time = time.time()
return outputs, end_time - start_time
def benchmark_model(model_path, num_iterations=100):
"""Benchmark the ONNX model."""
session = load_model(model_path)
input_data = generate_sample_input(session)
total_time = 0.0
for _ in range(num_iterations):
_, inference_time = run_inference(session, input_data)
total_time += inference_time
average_time = total_time / num_iterations
print(f"Average inference time over {num_iterations} iterations: {average_time:.6f} seconds")
if __name__ == "__main__":
model_path = "path/to/your/model.onnx"
benchmark_model(model_path)
Examples
Below is an example of running the onnxruntime_test Python script using the EfficientNet-Lite4 ONNX model for image classification on Genio 700:
root@genio-700-evk:~/onnxruntime_example# python3 onnxruntime_test.py -i kitten.jfif -l labels_map.txt -m /root/efficientnet-lite4/efficientnet-lite4.onnx
0.88291174 281: 'tabby, tabby cat',
0.093538865 285: 'Egyptian cat',
0.023412632 282: 'tiger cat',
3.1124982e-05 539: 'doormat, welcome mat',
1.9749632e-05 287: 'lynx, catamount',
time: 103.599ms
This example runs on 1 CPU thread using CPUExecutionProvider.
ONNX Runtime Execution Providers
ONNX Runtime supports various hardware acceleration libraries through its extensible Execution Providers (EP) framework, enabling optimal execution of ONNX models on different platforms. This flexibility allows developers to deploy ONNX models in diverse environments—cloud or edge—and optimize execution by leveraging the platform’s compute capabilities.
On Genio, the following execution providers are supported and integrated by default:
CPUExecutionProvider
XnnpackExecutionProvider
Both providers execute on CPU.
Quantization Methods
Quantization in ONNX Runtime refers to 8-bit linear quantization of ONNX models. For more information, see the official documentation: ONNX Runtime Quantization
Dynamic Quantization
Dynamic quantization calculates quantization parameters (scale and zero point) for activations dynamically during inference, typically resulting in higher accuracy at the cost of increased inference time.
import onnx
from onnxruntime.quantization import quantize_dynamic, QuantType
model_fp32 = 'path/to/the/model.onnx'
model_quant = 'path/to/the/model.quant.onnx'
quantized_model = quantize_dynamic(model_fp32, model_quant)
Static Quantization
Static quantization uses calibration data to determine quantization parameters, which are then stored in the quantized model. There are two static quantization formats:
QOperator (Operator-oriented): Quantized operators have their own ONNX definitions (e.g., QLinearConv, MatMulInteger).
QDQ (Tensor-oriented): Inserts QuantizeLinear and DeQuantizeLinear operators between original operators to simulate quantization and dequantization.
import onnx
import onnxruntime
from onnxruntime.quantization import quantize_static, CalibrationDataReader, QuantType, QuantFormat
import numpy as np
import argparse
class DummyCalibrationDataReader(CalibrationDataReader):
def __init__(self, input_name, input_shape, num_samples=100):
self.input_name = input_name
self.data = [{self.input_name: np.random.rand(*input_shape).astype(np.float32)} for _ in range(num_samples)]
self.iterator = iter(self.data)
def get_next(self):
return next(self.iterator, None)
def get_input_details(model_path):
model = onnx.load(model_path)
graph = model.graph
input_tensor = graph.input[0]
input_name = input_tensor.name
input_shape = [dim.dim_value for dim in input_tensor.type.tensor_type.shape.dim]
return input_name, input_shape
def quantize_model(fp32_model_path, int8_model_path):
input_name, input_shape = get_input_details(fp32_model_path)
calibration_data_reader = DummyCalibrationDataReader(input_name, input_shape)
quantize_static(fp32_model_path, int8_model_path, calibration_data_reader, quant_format=QuantFormat.QOperator, weight_type=QuantType.QInt8)
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Quantize FP32 ONNX model to INT8 using dummy inputs")
parser.add_argument("fp32_model_path", type=str, help="Path to the FP32 ONNX model")
parser.add_argument("int8_model_path", type=str, help="Path to save the INT8 ONNX model")
args = parser.parse_args()
quantize_model(args.fp32_model_path, args.int8_model_path)
print(f"Quantized model saved to {args.int8_model_path}")
Make Dynamic Shapes Static
Many ONNX models use dynamic shapes, which may not always be compatible with certain execution providers. In such cases, it is often necessary to convert dynamic shapes to static shapes. This conversion is typically performed on a host machine, after which the static ONNX model can be deployed to the target device for application use.
For more details, refer to the official documentation: ONNX Runtime: Make Dynamic Shape Fixed
Making Symbolic Dimensions Fixed
Consider a model (as visualized in Netron) with a symbolic dimension called batch for the batch size in input:0. We want to update this symbolic dimension to a fixed value, such as 1.
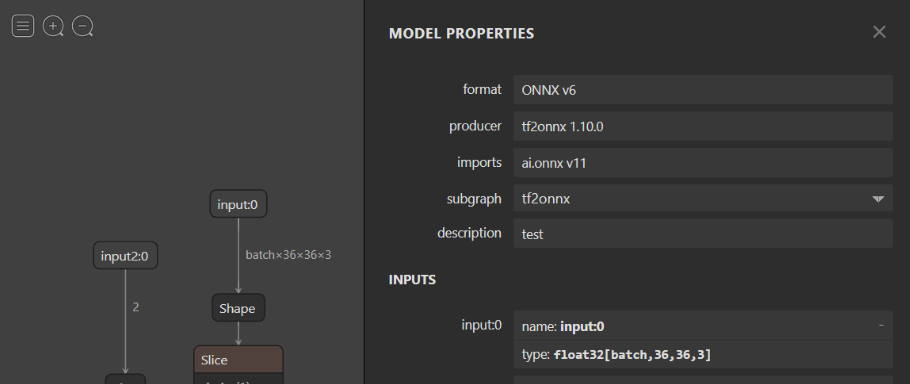
Example model with symbolic dimension
To convert the symbolic dimension to a static value, use the following Python command:
python3 -m onnxruntime.tools.make_dynamic_shape_fixed --dim_param batch --dim_value 1 model.onnx model.fixed.onnx
After this replacement, the shape for input:0 will be fixed to [1, 36, 36, 3].
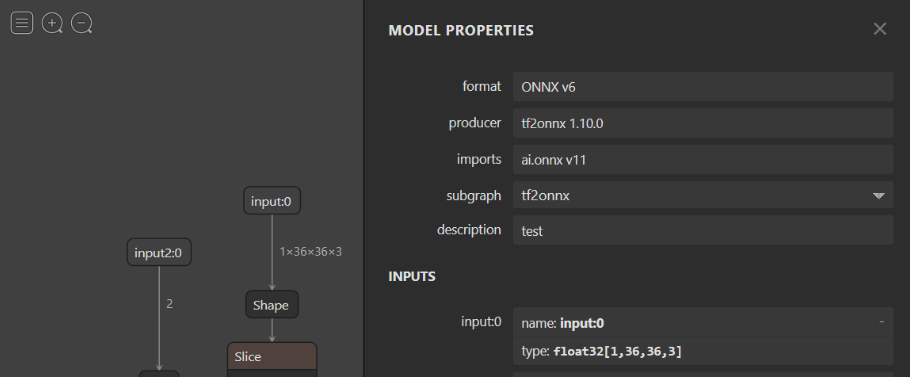
Example model with fixed dimension
Making Input Shape Fixed
Some models have unnamed dynamic dimensions, often represented as ? in Netron (for example, in the input x). Since these dimensions are unnamed, you can update the shape using the --input_shape option.
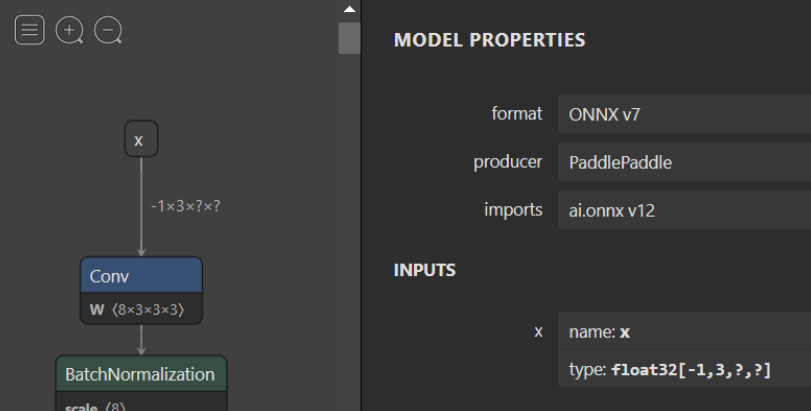
Example model with unnamed dynamic dimension
To fix these dynamic shapes, use the following command:
python3 -m onnxruntime.tools.make_dynamic_shape_fixed --input_name x --input_shape 1,3,960,960 model.onnx model.fixed.onnx
After running this command, the shape for x will be fixed to [1, 3, 960, 960].
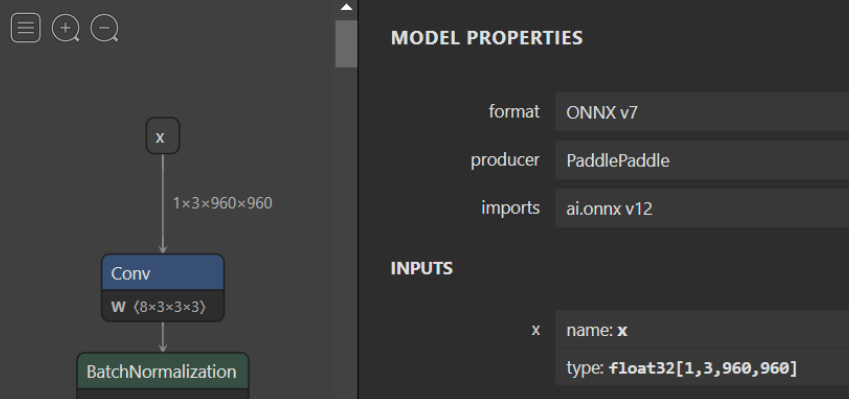
Example model with fixed dynamic dimension
ONNX TAO
For more information about TAO, please refer to the official documentation: MediaTek Genio TAO Documentation
ORT-GENAI
Genio supports ONNX Runtime GenAI packages, which are available as Python pip packages integrated into the Yocto build. Currently, this feature is in the experimental phase, and GenAI models are executed only on the CPU.
With the ONNX Runtime GenAI package, you can run models from the Phi family (text and vision) as well as DeepSeek on Genio. This enables the development of chatbots and experimentation with the conversational capabilities of small language models (SLMs). As of now, version 0.6 has been tested on Genio.
Note
This section will be updated as more features and support become available.