Genio 1200-EVK
MT8395 System on Chip
Hardware |
MT8395 |
|---|---|
CPU |
4x CA78 2.2GHz, 4x CA55 2.0GHz |
GPU |
ARM G57 |
AI |
APU 3.0 (2x MDLA 2.0, 2x VPU) |
Please refer to the MT8395 (Genio 1200) to find detailed specifications.
APU
The MediaTek AI Processing Unit (APU) is a high-performance hardware engine for deep-learning, optimized for bandwidth and power efficiency. The APU architecture consists of big, small, and tiny cores. This highly heterogeneous design is suited for a wide variety of modern smartphone tasks, such as AI-camera, AI-assistant, and OS or in-app enhancements.
The new APU 3.0 is scalable AI architecture, offering a huge 4 TOPS.
Overview
On Genio 1200-EVK, we provide different software solutions to boost AI computing by GPU and APU.
GPU Neural Network Acceleration
We provide tensorflow lite with hardware acceleration to develop and deploy
a wide range of machine learning. By using TensorFlow Lite Delegates,
you can enable hardware acceleration of TFLite models by leveraging on-device accelerators such as the GPU and Digital
Signal Processor (DSP)
IoT Yocto already integrated the following two delegates:
GPU delegate: The GPU delegate uses Open GL ES compute shader on the device to inference TFLite model.
Arm NN delegate: Arm NN is a set of open-source software that enables machine learning workloads on Arm hardware devices. It provides a bridge between existing neural network frameworks and Cortex-A CPUs, Arm Mali GPUs.
APU Neural Network Acceleration
We introduce the MediaTek-proprietary Machine Learning solution: NeuroPilot on IoT Yocto on MT8395 P1V6 demo board (deprecated in v23.1).
NeuroPilot is a collection of software tools and APIs which are at the center of MediaTek’s AI ecosystem. With NeuroPilot, users can develop and deploy AI applications on edge devices with extremely high efficiency. This makes a wide variety of AI applications run faster, while also keeping data private.
On Genio 1200-EVK, , we support online inference path Neuron Stable Delegate also offline inference path Neuron SDK
which is one of NeuroPilot software collections for APU acceleration.
For the Neuron Stable Delegate, it’s MTK neuron delegate implemented with the interface provided by TensorflowLite Stable.
Neuron SDK provides a Neuron compiler (ncc-tflite) to convert TFLite models to MediaTek-proprietary
binaries (DLA, Deep Learning Archive) for deployment on MediaTek platforms. The resulting models are highly
efficient, with reduced latency and a smaller memory footprint. Neuron SDK also provides Neuron Run-time API
which provides a set of APIs that users can invoke from within a C/C++ program to create a run-time environment,
parse compiled model file and perform on-device network inference.
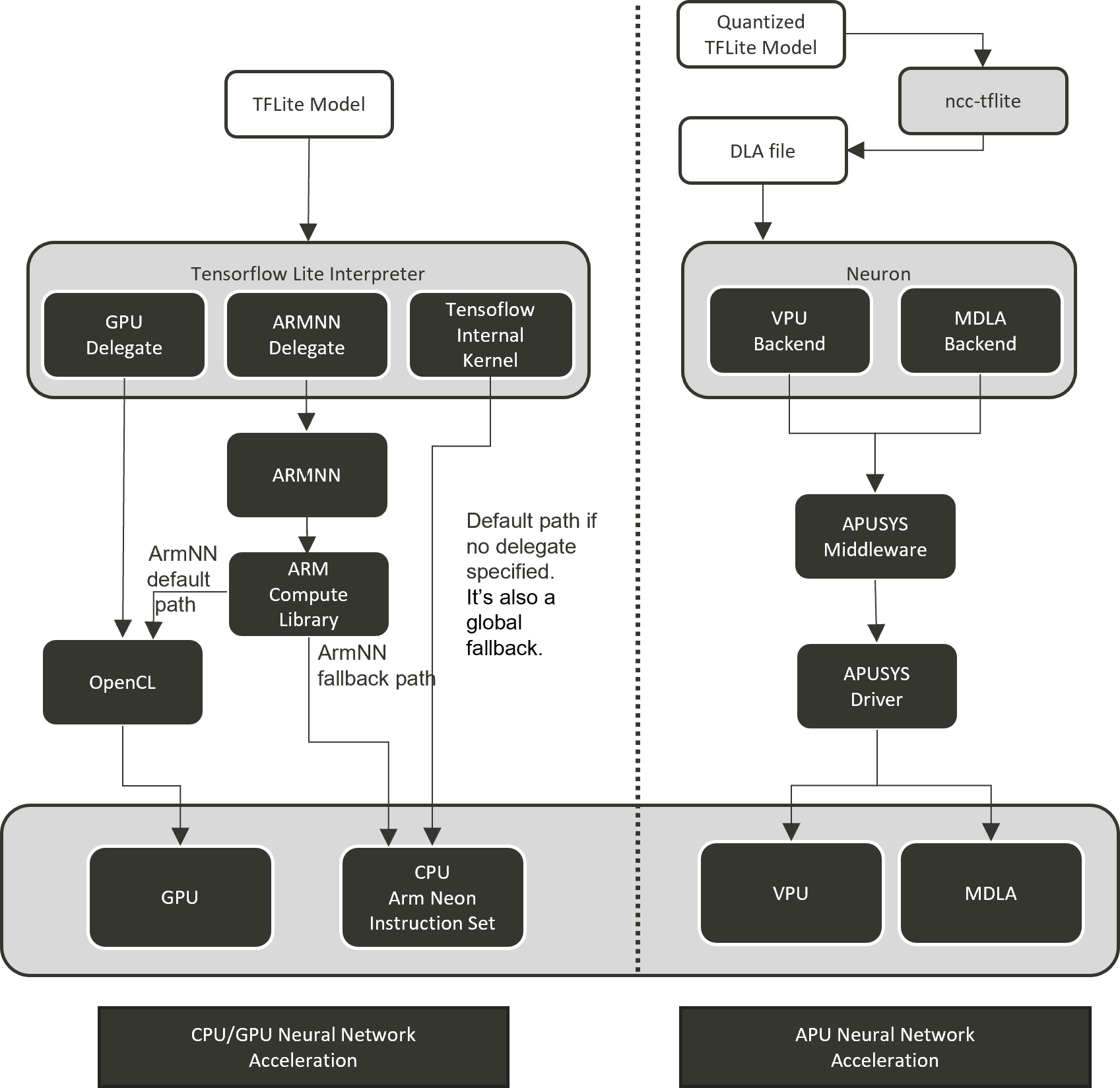
Machine learning software stack on Genio 1200-EVK
Note
Software information, cmd operations, and test results presented in this chapter are based on the latest version of IoT Yocto (v23.0), Genio 1200-EVK.
Tensorflow Lite and Delegates
IoT Yocto integrated the Tensorflow Lite and Arm NN delegate to provide GPU neural network acceleration.
The software versions are as follows:
Component |
Version |
Support Operations |
|---|---|---|
2.14.0 |
||
24.02 |
Note
According to Arm NN setup script, the Arm NN delegate unit tests are verified under TensorFlow Lite without XNNPACK support. In order to verify that the Arm NN delegate is properly integrated on IoT Yocto through its unit tests, IoT Yocto is configured not to enable XNNPACK support for TensorFlow Lite by default.
The following are the execution commands and results for the Arm NN delegate unit tests. All tests should pass. If XNNPACK is enabled in TensorFlow Lite, the Arm NN delegate unit tests will fail.
DelegateUnitTests
...
...
===============================================================================
[doctest] test cases: 670 | 670 passed | 0 failed | 0 skipped
[doctest] assertions: 53244 | 53244 passed | 0 failed |
[doctest] Status: SUCCESS!
Info: Shutdown time: 53.35 ms.
If you have to use Tensorflow Lite with XNNPACK, you can set the tflite_with_xnnpack as true in the following file: t/src/meta-nn/recipes-tensorflow/tensorflow-lite/tensorflow-lite_%.bbappend and rebuild Tensorflow Lite package.
CUSTOM_BAZEL_FLAGS += " --define tflite_with_xnnpack=true "
Supported Operations
TFLite 2.10.0 |
Arm NN 23.02 |
abs |
ABS |
add |
ADD |
add_n |
|
arg_max |
ARGMAX |
arg_min |
ARGMIN |
assign_variable |
|
average_pool_2d |
AVERAGE_POOL_2D |
AVERAGE_POOL_3D |
|
basic_lstm |
|
batch_matmul |
BATCH_MATMUL |
batch_to_space_nd |
BATCH_TO_SPACE_ND |
bidirectional_sequence_lstm |
|
broadcast_args |
|
broadcast_to |
|
bucketize |
|
call_once |
|
cast |
CAST |
ceil |
|
complex_abs |
|
concatenation |
CONCATENATION |
control_node |
|
conv_2d |
CONV_2D |
conv_3d |
CONV_3D |
conv_3d_transpose |
|
cos |
|
cumsum |
|
custom |
|
custom_tf |
|
densify |
|
depth_to_space |
DEPTH_TO_SPACE |
depthwise_conv_2d |
DEPTHWISE_CONV_2D |
dequantize |
DEQUANTIZE |
div |
DIV |
dynamic_update_slice |
|
elu |
ELU |
embedding_lookup |
|
equal |
EQUAL |
exp |
EXP |
expand_dims |
EXPAND_DIMS |
external_const |
|
fake_quant |
|
fill |
FILL |
floor |
FLOOR |
floor_div |
FLOOR_DIV |
floor_mod |
|
fully_connected |
FULLY_CONNECTED |
gather |
GATHER |
gather_nd |
GATHER_ND |
gelu |
|
greater |
GREATER |
greater_equal |
GREATER_EQUAL |
hard_swish |
HARD_SWISH |
hashtable |
|
hashtable_find |
|
hashtable_import |
|
hashtable_size |
|
if |
|
imag |
|
l2_normalization |
L2_NORMALIZATION |
L2_POOL_2D |
|
leaky_relu |
|
less |
LESS |
less_equal |
LESS_OR_EQUAL |
local_response_normalization |
LOCAL_RESPONSE_NORMALIZATION |
log |
LOG |
log_softmax |
LOG_SOFTMAX |
logical_and |
LOGICAL_AND |
logical_not |
LOGICAL_NOT |
logical_or |
LOGICAL_OR |
logistic |
LOGISTIC |
lstm |
LSTM |
matrix_diag |
|
matrix_set_diag |
|
max_pool_2d |
MAX_POOL_2D |
MAX_POOL_3D |
|
maximum |
MAXIMUM |
mean |
MEAN |
minimum |
MINIMUM |
mirror_pad |
MIRROR_PAD |
mul |
MUL |
multinomial |
|
neg |
NEG |
no_value |
|
non_max_suppression_v4 |
|
non_max_suppression_v5 |
|
not_equal |
NOT_EQUAL |
NumericVerify |
|
one_hot |
|
pack |
PACK |
pad |
PAD |
padv2 |
|
poly_call |
|
pow |
|
prelu |
PRELU |
pseudo_const |
|
pseudo_qconst |
|
pseudo_sparse_const |
|
pseudo_sparse_qconst |
|
quantize |
QUANTIZE |
random_standard_normal |
|
random_uniform |
|
range |
|
rank |
RANK |
read_variable |
|
real |
|
reduce_all |
|
reduce_any |
|
reduce_max |
REDUCE_MAX |
reduce_min |
REDUCE_MIN |
reduce_prod |
REDUCE_PROD |
relu |
RELU |
relu6 |
RELU6 |
relu_n1_to_1 |
RELU_N1_TO_1 |
reshape |
RESHAPE |
resize_bilinear |
RESIZE_BILINEAR |
resize_nearest_neighbor |
RESIZE_NEAREST_NEIGHBOR |
reverse_sequence |
|
reverse_v2 |
|
rfft2d |
|
round |
|
rsqrt |
RSQRT |
scatter_nd |
|
segment_sum |
|
select |
|
select_v2 |
|
shape |
SHAPE |
sin |
SIN |
slice |
|
softmax |
SOFTMAX |
space_to_batch_nd |
SPACE_TO_BATCH_ND |
space_to_depth |
SPACE_TO_DEPTH |
sparse_to_dense |
|
split |
SPLIT |
split_v |
SPLIT_V |
sqrt |
SQRT |
square |
|
squared_difference |
|
squeeze |
SQUEEZE |
strided_slice |
STRIDED_SLICE |
sub |
SUB |
sum |
SUM |
svdf |
|
tanh |
TANH |
tile |
|
topk_v2 |
|
transpose |
TRANSPOSE |
transpose_conv |
TRANSPOSE_CONV |
unidirectional_sequence_lstm |
UNIDIRECTIONAL_SEQUENCE_LSTM |
unidirectional_sequence_rnn |
|
unique |
|
unpack |
UNPACK |
unsorted_segment_max |
|
unsorted_segment_prod |
|
unsorted_segment_sum |
|
var_handle |
|
where |
|
while |
|
yield |
|
zeros_like |
Demo
A python demo application for image recognition is built in the image that can be found in the
/usr/share/label_image directory. It is adapted from the upstream
label_image.py
cd /usr/share/label_image
ls -l
-rw-r--r-- 1 root root 940650 Mar 9 2018 grace_hopper.bmp
-rw-r--r-- 1 root root 61306 Mar 9 2018 grace_hopper.jpg
-rw-r--r-- 1 root root 10479 Mar 9 2018 imagenet_slim_labels.txt
-rw-r--r-- 1 root root 95746802 Mar 9 2018 inception_v3_2016_08_28_frozen.pb
-rw-r--r-- 1 root root 4388 Mar 9 2018 label_image.py
-rw-r--r-- 1 root root 10484 Mar 9 2018 labels_mobilenet_quant_v1_224.txt
-rw-r--r-- 1 root root 4276352 Mar 9 2018 mobilenet_v1_1.0_224_quant.tflite
Basic commands for running the demo with different delegates are as follows.
Execute on CPU
cd /usr/share/label_image
python3 label_image.py --label_file labels_mobilenet_quant_v1_224.txt --image grace_hopper.jpg --model_file mobilenet_v1_1.0_224_quant.tflite
Execute on GPU, with GPU delegate
cd /usr/share/label_image
python3 label_image.py --label_file labels_mobilenet_quant_v1_224.txt --image grace_hopper.jpg --model_file mobilenet_v1_1.0_224_quant.tflite -e /usr/lib/gpu_external_delegate.so
Execute on GPU, with Arm NN delegate
cd /usr/share/label_image
python3 label_image.py --label_file labels_mobilenet_quant_v1_224.txt --image grace_hopper.jpg --model_file mobilenet_v1_1.0_224_quant.tflite -e /usr/lib/libarmnnDelegate.so.29 -o "backends:GpuAcc,CpuAcc"
Note
There is still no Tensorflow official support for python-binding on Stable Delegate by the date of Yocto v24.0 release.
Here we won’t have the Stable Delegate demo with python.
Benchmark Tool
benchmark_model is provided in Tenforflow Performance Measurement for performance evaluation.
Basic commands for running the benchmark tool with CPU and different delegates are as follows.
Execute on CPU (8 threads):
benchmark_model --graph=/usr/share/label_image/mobilenet_v1_1.0_224_quant.tflite --num_threads=8 --num_runs=10
Execute on GPU, with GPU delegate:
benchmark_model --graph=/usr/share/label_image/mobilenet_v1_1.0_224_quant.tflite --use_gpu=1 --gpu_precision_loss_allowed=1 --num_runs=10
Execute on GPU, with Arm NN delegate:
benchmark_model --graph=/usr/share/label_image/mobilenet_v1_1.0_224_quant.tflite --external_delegate_path=/usr/lib/libarmnnDelegate.so.29 --external_delegate_options="backends:GpuAcc,CpuAcc" --num_runs=10
Execute on APU, with Neuron Delegate:
benchmark_model --stable_delegate_settings_file=/usr/share/label_image/stable_delegate_settings.json --use_nnapi=false --use_xnnpack=false --use_gpu=false --min_secs=20 --graph=/usr/share/label_image/mobilenet_v1_1.0_224_quant.tflite
Neuron SDK
On Genio 1200-EVK, IoT Yocto supports Neuron SDK which is one of MediaTek NeuroPilot software collections.
Neuron SDK provides Neuron compiler (ncc-tflite) to convert TFLite models to MediaTek-proprietary
binaries (DLA, Deep Learning Archive) for deployment on MediaTek platforms. Neuron SDK also provides Neuron Run-time API
which provides a set of APIs that users can invoke from within a C/C++ program to create a run-time environment,
parse compiled model file and perform on-device network inference. Please refer to
Neuron SDK chapter to find all supporting detail.
Note
To enable Neuron SDK support on Genio 1200-EVK enable the apusys device tree overlay (apusys.dtbo) when flashing the image.
genio-flash --load-dtbo apusys.dtbo
Supported Operations
Refer to Supported Operations to find all the neural network operations supported by Neuron SDK, and any restrictions placed on their use.
Note
Different compute devices may have restrictions on supported operations. These restrictions are a function of:
Op Type
Op parameters (e.g. kernel dimensions and modifiers, such as stride)
Tensor dimensions (both input and output)
Soc Platform
Numeric format, both data type, and quantization method
Each device will have its guidelines and restrictions.
Demo
A python demo application for image recognition is built into the image
that can be found in the /usr/share/demo_dla directory.
cd /usr/share/demo_dla
ls -l
-rw-r--r-- 1 root root 61306 Mar 9 2018 grace_hopper.jpg
-rw-r--r-- 1 root root 10479 Mar 9 2018 imagenet_slim_labels.txt
-rw-r--r-- 1 root root 1402 Mar 9 2018 label_image.py
-rw-r--r-- 1 root root 4276352 Mar 9 2018 mobilenet_v1_1.0_224_quant.tflite
Use cmd:python3 label_image.py to run the demo. The demo program will convert mobilenet_v1_1.0_224_quant.tflite
into DLA, then inference it on APU to classify the image: grace_hopper.jpg. Finally, print out the result of
image classification, it should be “military uniform”.
cd /usr/share/demo_dla
python3 label_image.py
/usr/share/demo_dla/mobilenet_v1_1.0_224_quant.dla
/usr/share/demo_dla/grace_hopper.bin
WARNING: dlopen failed: libcmdl_ndk.mtk.vndk.so and libcmdl_ndk.mtk.so not found
WARNING: CmdlLibManager cannot get dlopen handle.
[apusys][info]apusysSession: Session(0xaaaaf9d4eb80): thd(runtime_api_sam) version(3) log(0)
The required size of the input buffer is 150528
The required size of the output buffer is 1001
[apusys][info]run: Cmd v2(0xaaaaf9d737e0): run
[apusys][info]run: Cmd v2(0xaaaaf9d737e0): run done(0)
The top index is 653
The image: military uniform
Benchmark Tool
A python application for benchmarking is built in the image
that can be found in the /usr/share/benchmark_dla directory.
cd /usr/share/benchmark_dla
ls -l
-rw-r--r-- 1 root root 26539112 Mar 9 2018 ResNet50V2_224_1.0_quant.tflite
-rw-r--r-- 1 root root 9020 Mar 9 2018 benchmark.py
-rw-r--r-- 1 root root 23942928 Mar 9 2018 inception_v3_quant.tflite
-rw-r--r-- 1 root root 3577760 Mar 9 2018 mobilenet_v2_1.0_224_quant.tflite
-rw-r--r-- 1 root root 6885840 Mar 9 2018 ssd_mobilenet_v1_coco_quantized.tflite
Use cmd:python3 benchmark.py --auto to run the benchmark. It will find all TFLite models in
/usr/share/benchmark_dla and compile them into DLA, then inference them on APU. Finally, the
benchmark result will be saved in /usr/share/benchmark_dla/benchmark.log
cd /usr/share/benchmark_dla
# run benchmark to evaluate inference time of each model in the current folder
python3 benchmark.py --auto
# check inference time of each model
cat benchmark.log
[INFO] mobilenet_v2_1.0_224_quant.tflite, mdla2.0, avg inference time: 3.2
[INFO] mobilenet_v2_1.0_224_quant.tflite, vpu, avg inference time: 14.1
[INFO] ssd_mobilenet_v1_coco_quantized.tflite, mdla2.0, avg inference time: 4.2
[INFO] ssd_mobilenet_v1_coco_quantized.tflite, vpu, avg inference time: 20.1
[INFO] ResNet50V2_224_1.0_quant.tflite, mdla2.0, avg inference time: 8.2
[INFO] ResNet50V2_224_1.0_quant.tflite, vpu, avg inference time: 56.3
[INFO] inception_v3_quant.tflite, mdla2.0, avg inference time: 11.2
[INFO] inception_v3_quant.tflite, vpu, avg inference time: 71.4
Benchmark Result
The following table are the benchmark results under performance mode
Run model (.tflite) 10 times |
CPU (Thread:8) |
GPU |
ARMNN(GpuAcc) |
ARMNN(CpuAcc) |
Neuron Stable |
APU(MDLA 2.0) |
APU(VPU) |
inception_v3 |
122.892 |
119.858 |
79.71 |
73.626 |
20.09 |
20.5 |
|
inception_v3_quant |
34.783 |
119.36 |
48.013 |
29.062 |
9.26 |
9.05 |
74 |
mobilenet_v2_1.0.224 |
12.257 |
9.922 |
10.774 |
8.589 |
3.24 |
3.05 |
|
mobilenet_v2_1.0.224_quant |
6.545 |
9.859 |
9.31 |
4.287 |
1.57 |
1.05 |
17 |
ResNet50V2_224_1.0 |
93.113 |
70.487 |
56.633 |
58.04 |
14.59 |
14.05 |
|
ResNet50V2_224_1.0_quant |
39.116 |
72.569 |
28.887 |
22.733 |
6.44 |
6.05 |
59 |
ssd_mobilenet_v1_coco |
30.674 |
30.06 |
25.131 |
28.373 |
6.93 |
7.05 |
|
ssd_mobilenet_v1_coco_quantized |
10.173 |
32.344 |
17.313 |
9.026 |
2.91 |
2.76 |
23.57 |
Performance Mode
Force CPU, GPU, APU to run at maximum frequency.
CPU at maximum frequency
Command to set performance mode for CPU governor.
echo performance > /sys/devices/system/cpu/cpufreq/policy0/scaling_governor echo performance > /sys/devices/system/cpu/cpufreq/policy4/scaling_governor
Disable CPU idle
Command to disable CPU idle.
for j in 2 1 0; do for i in 7 6 5 4 3 2 1 0 ; do echo 1 > /sys/devices/system/cpu/cpu$i/cpuidle/state$j/disable ; done ; doneGPU at maximum frequency
Please refer to Adjust GPU Frequency to fix GPU to run at maximum frequency.
Or you could just set performance mode for GPU governor, and make the GPU statically to the highest frequency.
echo performance > /sys/devices/platform/soc/13000000.mali/devfreq/13000000.mali/governorAPU Performance Hints
The APU operates in performance mode by default, so no adjustments are necessary. To reduce performance, refer to the QoS Tuning Flow and set lower
qos.boostValuevalues.If you suspect a performance issue related to APUSYS frequency, use the following DebugFS node to force APUSYS to run at the highest operating points. Then, compare the actual model inference time for any differences:
echo dvfs_debug 0 > /sys/kernel/debug/apusys/powerWarning
Note that this is a debug feature and should not be used in production images. As a general guideline, kernel DebugFS should be disabled in production environments.
Disable thermal
echo disabled > /sys/class/thermal/thermal_zone0/mode