ONNX Runtime - Analytical AI
ONNX Runtime is a high-performance, cross-platform engine for running and training machine learning models in the Open Neural Network Exchange (ONNX) format. It accelerates inference and training for models from popular frameworks such as PyTorch and TensorFlow, leveraging hardware accelerators and graph optimizations for optimal performance.
ONNX Runtime on Genio
Genio platforms execute ONNX models efficiently through pre-integrated support. The current supported version on IoT Yocto is v1.20.2. Starting from Rity v25.1, the Board Support Package (BSP) provides prebuilt ONNX Runtime binaries.
Note
The rity-demo-image includes prebuilt ONNX Runtime packages by default.
ONNX Runtime Workflow on Yocto
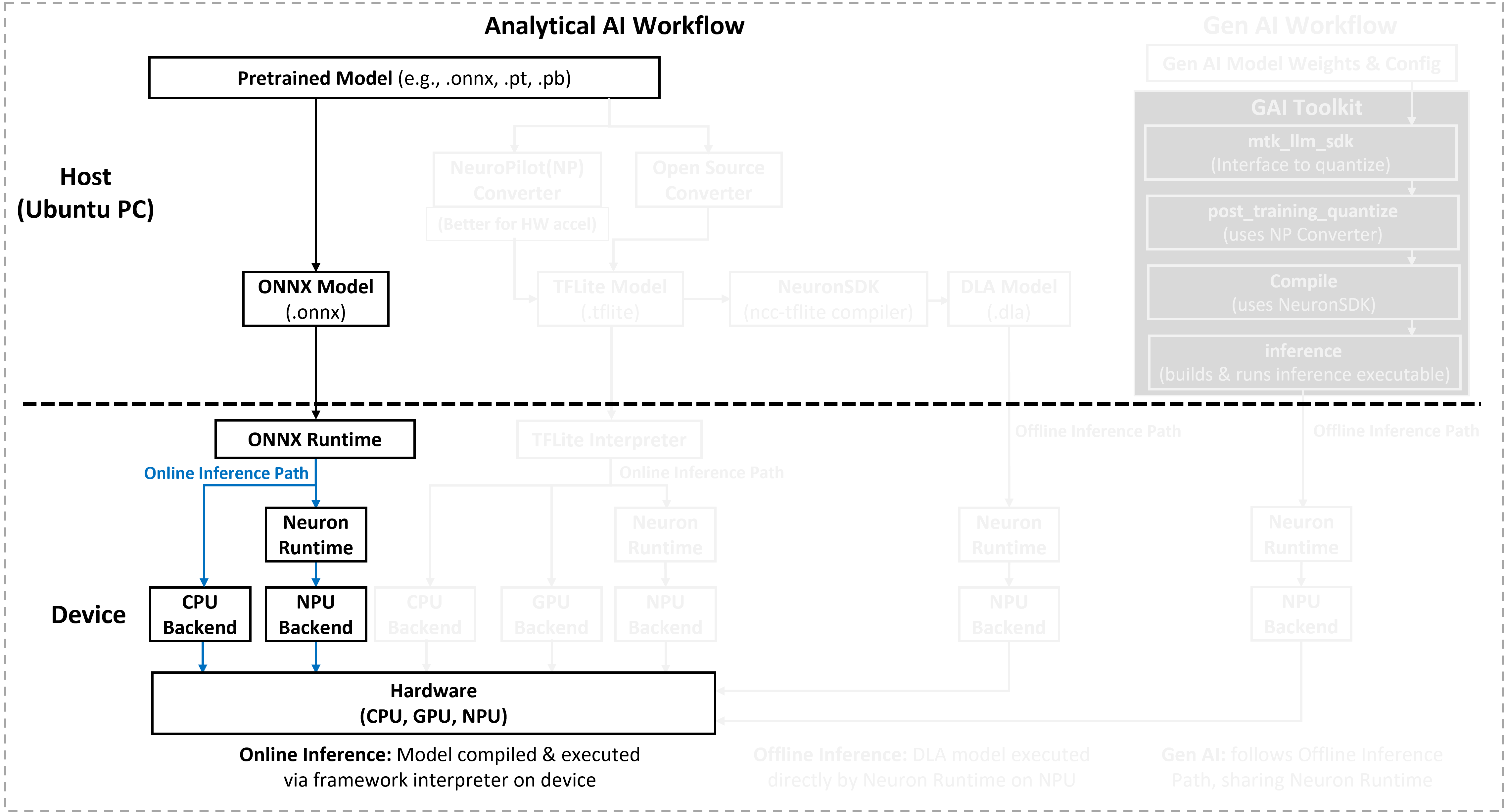
The following figure illustrates the analytical AI workflow for ONNX Runtime on Genio Yocto platforms. It shows the path from the ONNX model to hardware execution through the ONNX Runtime and its associated execution providers.
To add ONNX Runtime to a custom Rity image, the developer must perform the following steps:
Initialize the repository:
repo init -u https://gitlab.com/mediatek/aiot/bsp/manifest.git -b refs/tags/rity-scarthgap-v25.1
Synchronize the repository:
repo sync -j 12
Modify the configuration:
Add the following line to the
local.conffile:IMAGE_INSTALL:append = " onnxruntime-prebuilt "
Build the image:
bitbake rity-demo-image
Basic Inference on Genio
Once ONNX Runtime is integrated, the developer can execute models using the Python API. The following script provides a template for benchmarking ONNX models on the CPU using the XnnpackExecutionProvider.
import onnxruntime as ort
import numpy as np
import time
def load_model(model_path):
session_options = ort.SessionOptions()
session_options.intra_op_num_threads = 4
session_options.graph_optimization_level = ort.GraphOptimizationLevel.ORT_ENABLE_ALL
# Use XNNPACK for optimized CPU execution
execution_providers = ['XnnpackExecutionProvider', 'CPUExecutionProvider']
return ort.InferenceSession(model_path, sess_options=session_options, providers=execution_providers)
def benchmark_model(model_path, num_iterations=100):
session = load_model(model_path)
input_meta = session.get_inputs()[0]
input_data = {input_meta.name: np.random.random(input_meta.shape).astype(np.float32)}
total_time = 0.0
for _ in range(num_iterations):
start_time = time.time()
session.run(None, input_data)
total_time += (time.time() - start_time)
print(f"Average inference time: {total_time / num_iterations:.6f} seconds")
if __name__ == "__main__":
benchmark_model("your_model.onnx")