TFLite(LiteRT) - Generative AI
Important
MediaTek currently supports Generative AI (GAI) only on the Android OS. The performance results and model capabilities described in this section represent the Android software stack. Genio 520 and Genio 720 Yocto platforms will support GAI in 2026 Q2.
The Generative Model section provides performance and capability data for large language models (LLMs), vision-language models (VLMs) and image generation models on MediaTek Genio platforms.
This section is intended as a reference for benchmarking and platform capability validation, not as a distribution channel for full training or deployment assets.
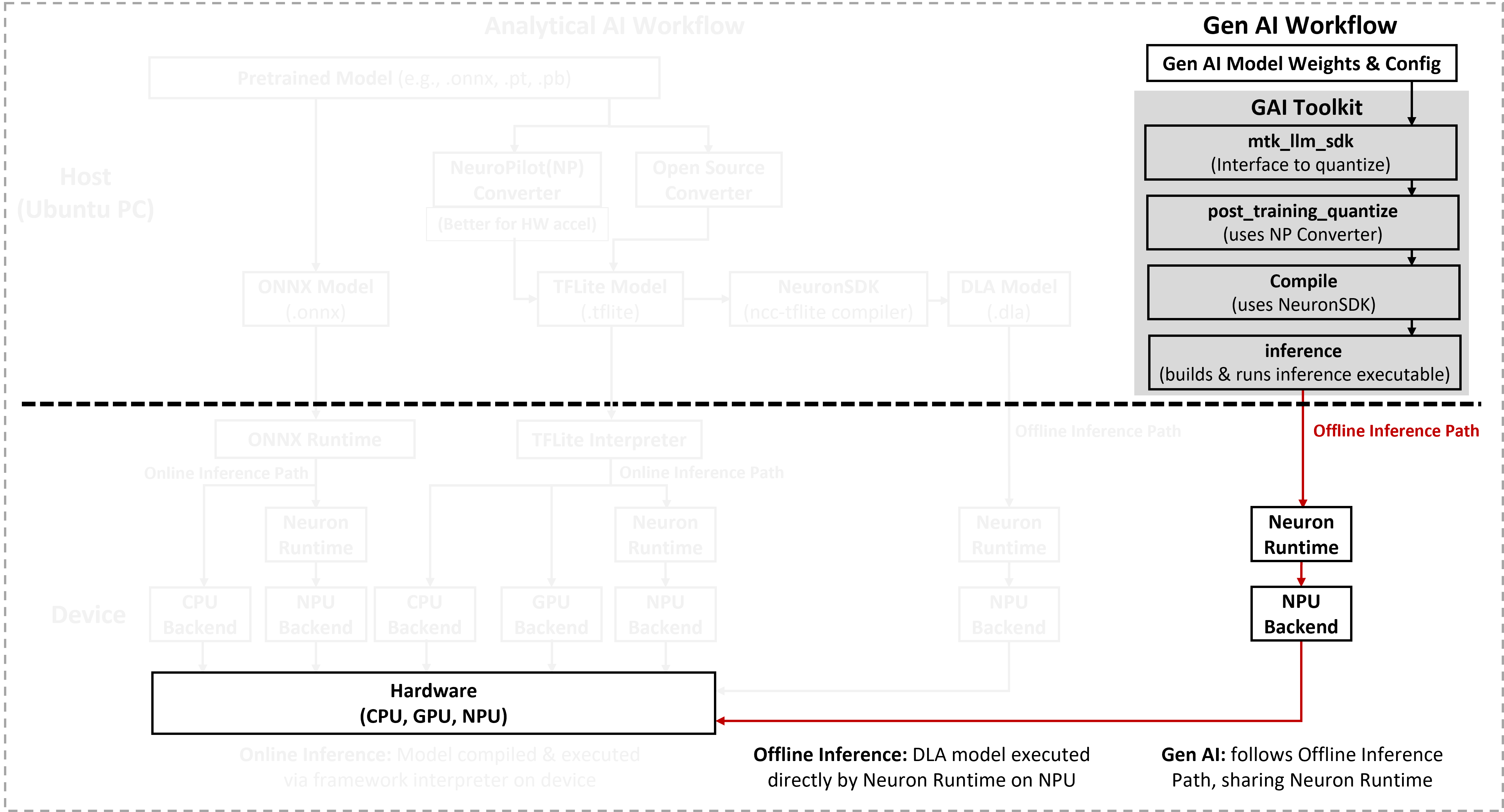
Note
For Generative AI workloads, this section provides performance data and capability information only.
Access to the full Generative AI deployment toolkit (GAI toolkit) requires a non-disclosure agreement (NDA) with MediaTek. After signing an NDA, the toolkit can be downloaded from NeuroPilot Document.
Model Categories
The generative models in this section are grouped into the following categories:
Large Language Models (LLMs) – Text-only models for tasks such as dialogue, summarization, and code generation.
Vision-Language Models (VLMs) – Multimodal models that process both images and text (for example, image captioning or visual question answering).
Image Generation and Enhancement – Models such as Stable Diffusion and other diffusion or transformer-based pipelines used for image synthesis, editing, or super-resolution.
Embedding and Encoder Models – Models like CLIP encoders for computing joint image-text embeddings for retrieval or ranking tasks.
Supported Models on Genio Products
Platform-specific model lists and performance data are provided in the following pages:
Performance Notes and Limitations
For Generative AI workloads, measured performance on Genio 520 may be slightly lower than on Genio 720.
This gap is primarily due to DRAM bandwidth differences between the two platforms and might affect:
Token generation speed for LLMs.
End-to-end latency for diffusion-based image generation.
Multimodal pipelines that exchange large intermediate tensors between subsystems.
The following comparative data is provided for reference.
Important
The tables in this section provide representative numbers only. To obtain the most accurate performance for a specific use case, developers must deploy and run the workload directly on the target platform under the intended system configuration.
LLM Performance Comparison
Model |
Genio 360 |
Genio 420 |
Genio 520 |
Genio 720 |
MT8883 |
MT8893 |
|---|---|---|---|---|---|---|
DeepSeek-R1-Distill-Qwen-1.5B |
– |
– |
276.82 |
341.69 |
– |
1057.25 |
DeepSeek-R1-Distill-Qwen-7B |
– |
– |
Not Support |
69.23 |
– |
448.17 |
DeepSeek-R1-Distill-Llama-8B |
– |
– |
Not Support |
36.65 |
– |
425.79 |
Qwen3-1.7B |
159.19 |
218.85 |
229.63 |
233.03 |
834.02 |
1069.16 |
Qwen2.5-1.5B-Instruct |
210.99 |
291.13 |
269.87 |
341.42 |
763.66 |
1621.85 |
Qwen2.5-3B-Instruct |
– |
– |
Not Support |
162.48 |
502.05 |
751.06 |
Qwen2.5-7B-Instruct |
– |
– |
Not Support |
70.55 |
184.73 |
471.95 |
gemma3-1B (Text Only) |
333.71 |
492.98 |
491.53 |
603.15 |
1125.16 |
– |
gemma3-4B (Text-Only) |
– |
– |
– |
156.89 |
– |
– |
gemma2-2b-it |
– |
– |
Not Support |
193.39 |
– |
891.00 |
llama3.2-1B-Instruct |
245.86 |
331.70 |
335.92 |
401.29 |
1372.57 |
2093.61 |
llama3.2-3B-Instruct |
– |
– |
Not Support |
154.56 |
611.76 |
1022.95 |
llama3-8b |
– |
– |
Not Support |
56.50 |
128.36 |
426.13 |
MiniCPM-2B-sft-bf16-llama-format |
– |
– |
153.14 |
194.79 |
– |
886.72 |
llava1.5-7b-speculative-decoding |
– |
– |
Not Support |
73.10 |
138.76 |
267.98 |
medusa_v1_0_vicuna_7b_v1.5 |
– |
– |
Not Support |
91.82 |
– |
501.05 |
vicuna1.5-7b-tree-speculative-decoding-plus |
– |
– |
Not Support |
84.90 |
– |
454.58 |
baichuan-7b-int8-cache |
– |
– |
Not Support |
81.18 |
– |
561.76 |
Model |
Genio 360 |
Genio 420 |
Genio 520 |
Genio 720 |
MT8883 |
MT8893 |
|---|---|---|---|---|---|---|
DeepSeek-R1-Distill-Qwen-1.5B |
– |
– |
9.18 |
11.76 |
– |
25.68 |
DeepSeek-R1-Distill-Qwen-7B |
– |
– |
Not Support |
4.68 |
– |
11.69 |
DeepSeek-R1-Distill-Llama-8B |
– |
– |
Not Support |
4.58 |
– |
11.36 |
Qwen3-1.7B |
5.88 |
12.04 |
10.53 |
10.91 |
25.18 |
23.42 |
Qwen2.5-1.5B-Instruct |
9.97 |
17.92 |
15.11 |
18.43 |
20.16 |
38.57 |
Qwen2.5-3B-Instruct |
– |
– |
Not Support |
10.31 |
19.32 |
20.87 |
Qwen2.5-7B-Instruct |
– |
– |
Not Support |
4.89 |
6.89 |
11.74 |
gemma3-1B (Text Only) |
10.60 |
23.94 |
22.13 |
26.49 |
38.87 |
– |
gemma3-4B (Text-Only) |
– |
– |
– |
8.01 |
– |
– |
gemma2-2b-it |
– |
– |
Not Support |
8.75 |
– |
21.37 |
llama3.2-1B-Instruct |
13.84 |
22.55 |
20.59 |
24.53 |
43.47 |
61.14 |
llama3.2-3B-Instruct |
– |
– |
Not Support |
10.58 |
19.89 |
25.05 |
llama3-8b |
– |
– |
Not Support |
4.70 |
6.53 |
11.51 |
MiniCPM-2B-sft-bf16-llama-format |
– |
– |
6.48 |
7.69 |
– |
22.28 |
llava1.5-7b-speculative-decoding |
– |
– |
Not Support |
7.28 |
4.46 |
6.78 |
medusa_v1_0_vicuna_7b_v1.5 |
– |
– |
Not Support |
10.56 |
– |
22.79 |
vicuna1.5-7b-tree-speculative-decoding-plus |
– |
– |
Not Support |
12.65 |
– |
22.72 |
baichuan-7b-int8-cache |
– |
– |
Not Support |
4.24 |
– |
11.37 |
Stable Diffusion Performance Comparison
Model |
Genio 720 |
Genio 520 |
MT8893 |
|---|---|---|---|
Stable Diffusion v.1.5 controlnet |
33642 |
47923 |
9395 |
Stable Diffusion v2.1 base model with controlnet |
31183 |
Not Support |
6969 |
Model |
Genio 720 |
Genio 520 |
MT8893 |
|---|---|---|---|
Stable Diffusion v.1.5 controlnet |
32294 |
37581 |
8035 |
Stable Diffusion v2.1 base model with controlnet |
29828 |
Not Support |
5451 |
CLIP Performance Comparison
Model |
Genio 720 |
Genio 520 |
MT8893 |
|---|---|---|---|
img_encoder_proj_clip_vit_large_dynamic |
567.61 |
662.22 |
358.61 |
img_encoder_proj_openclip_vit_big_g_dynamic |
12035.52 |
Not Support |
1390.56 |
img_encoder_proj_openclip_vit_h_dynamic |
1440.20 |
Not Support |
591.93 |
text_encoder_clip_vit_large |
455.08 |
748.45 |
308.72 |
text_encoder_openclip_vit_h |
750.70 |
Not Support |
510.92 |
Model |
Genio 720 |
Genio 520 |
MT8893 |
|---|---|---|---|
img_encoder_proj_clip_vit_large_dynamic |
257.39 |
296.84 |
51.14 |
img_encoder_proj_openclip_vit_big_g_dynamic |
3142.96 |
Not Support |
517.13 |
img_encoder_proj_openclip_vit_h_dynamic |
881.65 |
Not Support |
147.47 |
text_encoder_clip_vit_large |
38.99 |
45.56 |
18.94 |
text_encoder_openclip_vit_h |
119.77 |
Not Support |
48.49 |
Note
For VLM, Qwen3-vl is to be released by the end of June,2026.
Deployment and Source Models
The generative models referenced in this section are primarily intended for benchmarking and capability validation.
Model accuracy and qualitative output quality are not addressed.
MediaTek does not redistribute original training datasets or checkpoint files for third-party or open-source models.
For production deployment, developers must:
Obtain the original models from their official sources,
Follow the applicable licenses and usage terms, and
Perform any required fine-tuning or post-training optimization for your application.