TFLite(LiteRT) - Analytical AI
Overview
TFLite serves as the primary inference engine for analytical AI on MediaTek Genio platforms. This section describes the TFLite ecosystem, its internal architecture, and the built-in tools available for evaluation and development.
To understand the role of TFLite within the Genio environment, developers must view it both as a component of the broader analytical AI workflow and as a standalone runtime ecosystem.
High-Level Context
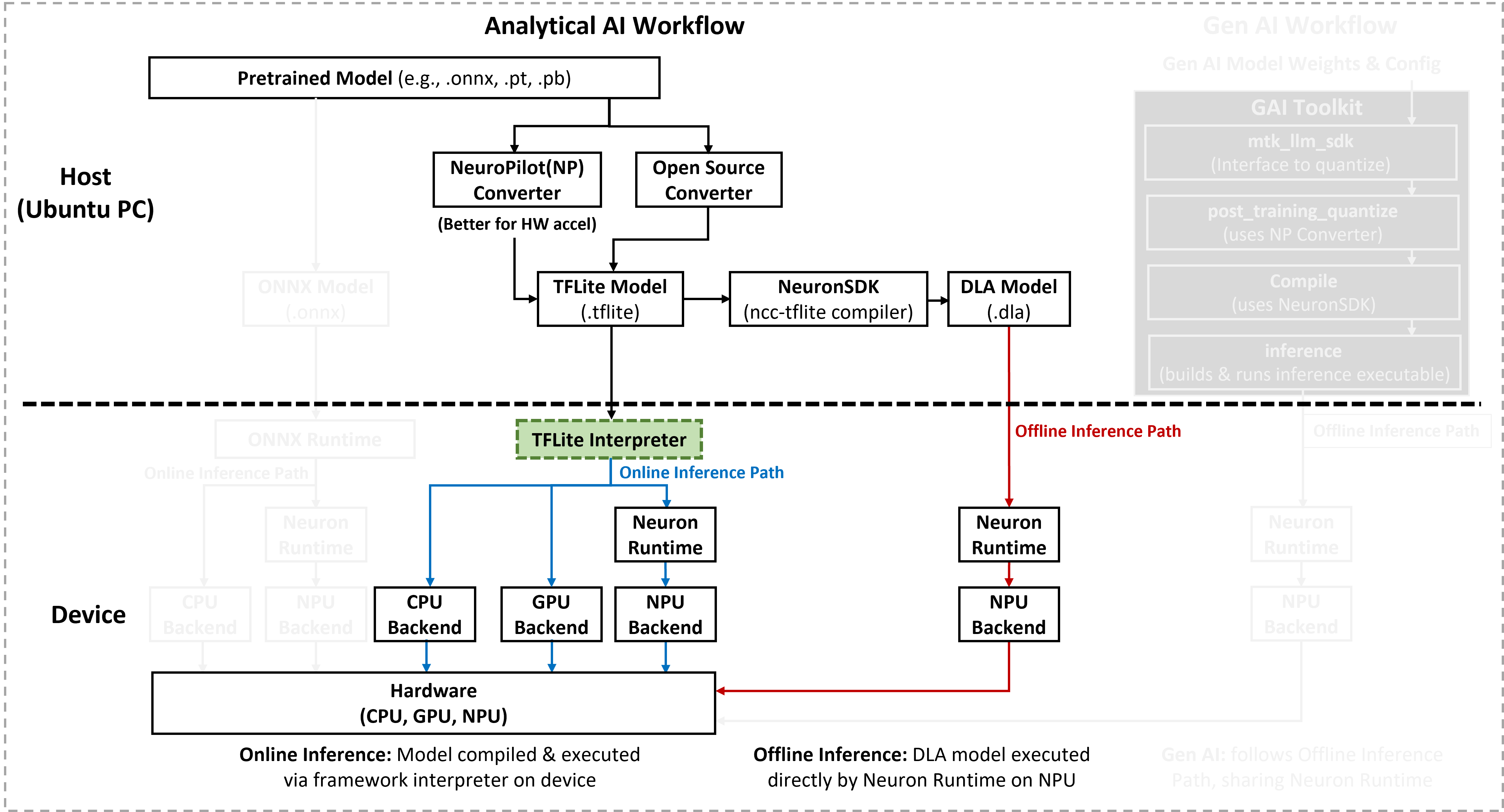
The following figure identifies the TFLite Interpreter as the core engine for online inference within the analytical AI path. While models are prepared on a host (PC), the Interpreter manages the final execution and hardware delegation on the Genio device.
Detailed Ecosystem and Delegation
The figure below provides a detailed view of the TFLite ecosystem on MediaTek platforms. It illustrates how the TFLite Interpreter acts as a central dispatcher, using delegates to dispatch specific operations to optimized hardware backends.
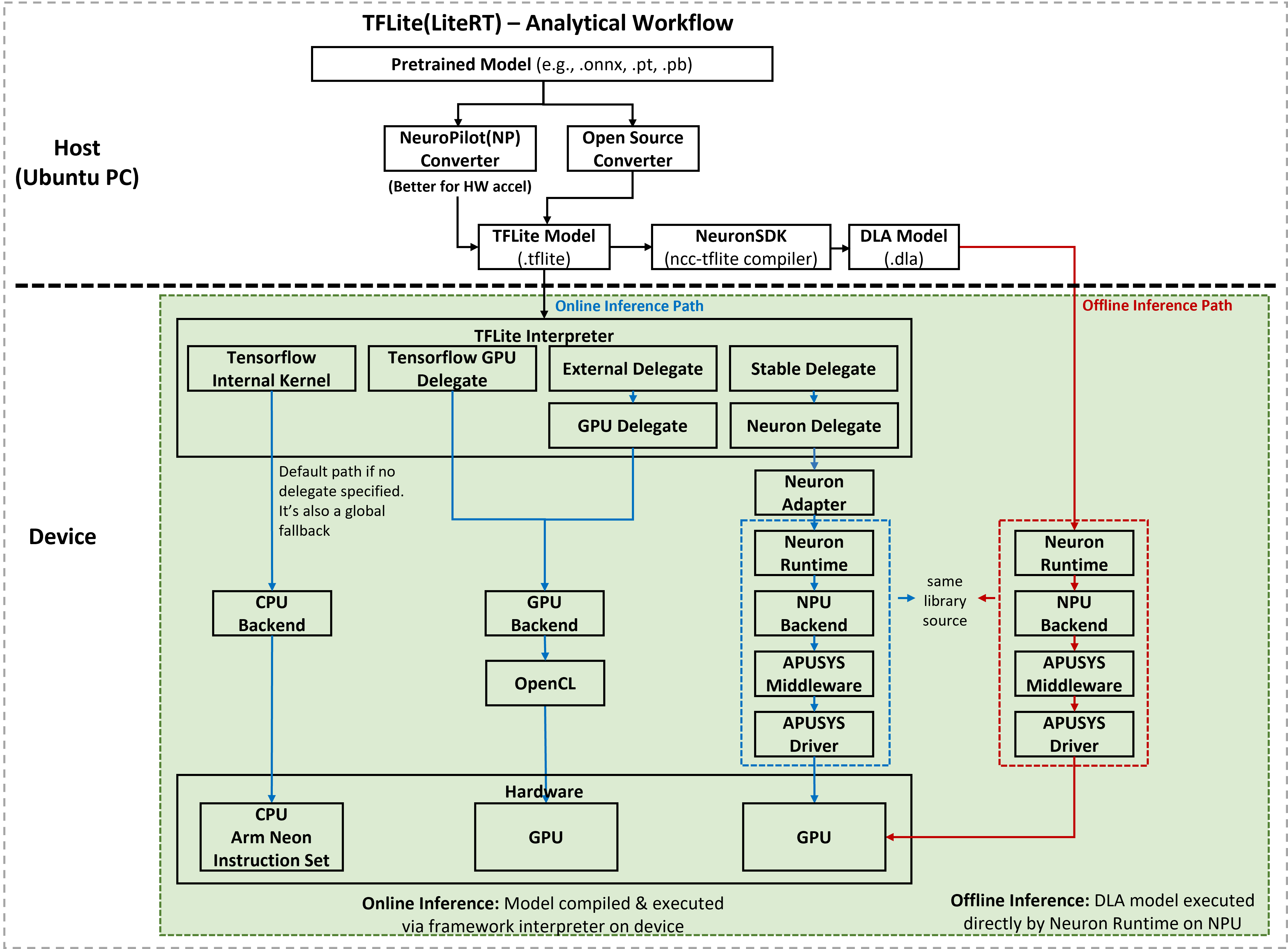
To optimize AI performance, the Interpreter dispatches workloads through three primary execution paths: CPU, GPU, and NPU.
Standard CPU Path (Default and Fallback)
This path ensures model execution integrity. If no delegate is specified, or if an operation is not supported by hardware accelerators, the Interpreter falls back to the CPU.
Component |
Source |
Function |
|---|---|---|
TensorFlow Internal Kernel |
Google (Open Source) |
Provides the reference implementation for all standard TFLite operators. |
CPU Backend |
Arm (Open Source) |
Executes operations on the ARM Neon instruction set for universal compatibility. |
GPU Acceleration Path
The GPU path is suitable for various vision and multimedia inference scenarios that benefit from parallel processing.
Component |
Source |
Function |
|---|---|---|
TensorFlow GPU Delegate |
Google (Open Source) |
Interfaces with the Interpreter to offload a broad set of vision-related operators. |
GPU Backend (OpenCL) |
Google (Open Source) |
Utilizes OpenGL ES compute shaders and OpenCL to run workloads on the Mali GPU. |
NPU Acceleration Path (NeuroPilot)
This path provides the highest efficiency and performance for supported neural network operations by utilizing MediaTek’s dedicated AI hardware.
Component |
Source |
Function |
|---|---|---|
Stable Delegate |
Google (Open Source) |
Provides a stable ABI (Application Binary Interface) for hardware vendor integrations. |
Neuron Delegate |
MediaTek (Proprietary) |
Acts as the MediaTek-specific implementation of the TFLite Stable Delegate. |
Neuron Adapter / Runtime |
MediaTek (Proprietary) |
Manages model compilation on-device and schedules tasks across NPU engines. |
VPU / MDLA Backends |
MediaTek (Proprietary) |
Dedicated hardware engines (Video Processing Unit and Deep Learning Accelerator) for AI inference. |
Note
On evaluation boards with an MDLA-enabled SoC (all Genio platforms except Genio 350), TFLite supports both the online inference path and the offline inference path.
For a detailed comparison of these deployment strategies and their respective workflows, refer to Software Architecture. Additional technical discussions are available on the Genio Community forum.
Built-In Tools and Applications (Yocto)
The IoT Yocto distribution includes several built-in benchmarking tools and demonstration applications. These resources enable developers to evaluate hardware performance and verify TFLite integration immediately after booting the system.
Performance Benchmarking
MediaTek provides the benchmark_tool to measure inference latency and resource utilization across different hardware backends. This tool includes:
Online Inference Benchmarks: Based on the upstream
benchmark_modelutility.Offline Inference Benchmarks: A Python-based application
benchmark.pyfor driving compiled DLA models through the Neuron runtime.
For usage instructions, see Benchmark Tool.
Demonstration Applications
To illustrate real-world integration, the Yocto image provides two primary demo frameworks:
Label Image: A classic image classification example using
label_image.pyto demonstrate basic TFLite Interpreter usage and hardware delegation. Refer to Label Image.NNStreamer: A powerful GStreamer-based framework for building efficient AI pipelines. MediaTek provides a dedicated
tensor_filtersubplugin for the Neuron SDK. Refer to NNStreamer.