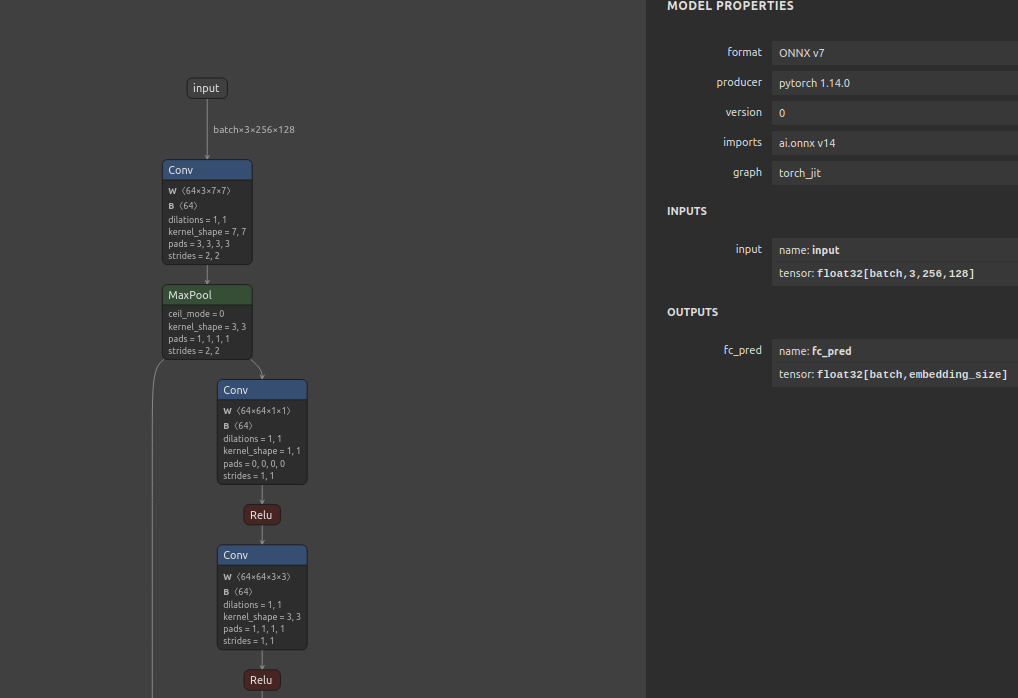
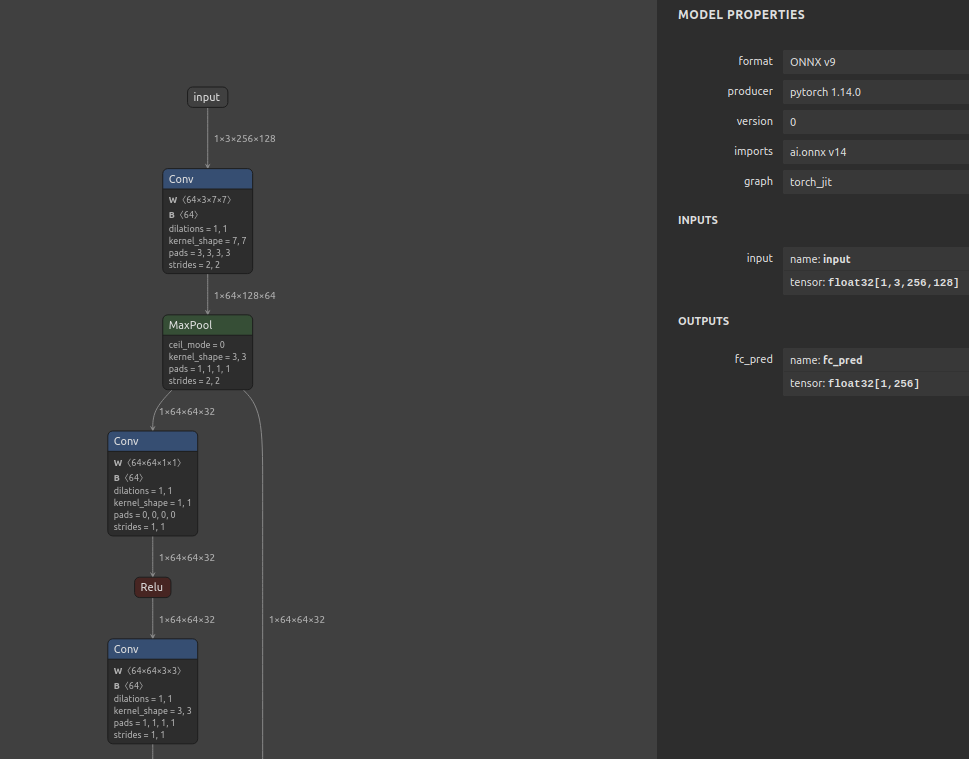
In this tutorial, we will guide you through the steps to take the ReidentificationNet model from the NVIDIA NGC hub, convert the ONNX model to TFLite format, quantize and execute them on the TFLite benchmark model. We will demonstrate two conversion methods: using the open-source onnx2tf tool and MediaTek’s proprietary mtk-converter. Finally, we will showcase a demo video of an application created using the same model.
onnx2tf is an open-source tool that converts ONNX models to TensorFlow Lite models. It is designed to be easy to use and supports a wide range of ONNX operators. This method is suitable for users who prefer open-source solutions and want to leverage the flexibility of TensorFlow Lite.
This will generate the TF saved_model which can be further used for quantization using MLIR.
Convert and Quantize the Model to TFLite:
We can use the generated TF saved_model and convert it to TFLite using the TFLite converter.
importtensorflowastfimportnumpyasnptf_model_path='/path/to/saved_model'tflite_model_path='resnet50_market1501_aicity156.tflite'# Generate representative datasetdefrepresentative_dataset():data=tf.random.uniform((1,256,128,3))yield[data]converter=tf.lite.TFLiteConverter.from_saved_model(tf_model_path)converter.optimizations=[tf.lite.Optimize.DEFAULT]# ================================================================# To quantize the model, add the below snippetconverter.representative_dataset=representative_dataset()converter.target_spec.supported_ops=[tf.lite.OpsSet.TFLITE_BUILTINS_INT8]converter.inference_input_type=tf.int8## Can be tf.uint8, or tf.float32 or tf.float16# converter.inference_output_type = tf.int8 ## Can be tf.uint8, tf.float32 or tf.float16. We keep it float32 for ease of post-processing output data# DO NOTE: THE MODEL OUTPUTS WILL ALWAYS BE INT64# ================================================================tflite_model=converter.convert()withopen(tflite_model_path,"wb")asf:f.write(tflite_model)
mtk-converter is MediaTek’s proprietary tool for converting ONNX models to TFLite format. It is optimized for MediaTek’s hardware and provides additional features for model optimization and deployment. This method is recommended for users who are deploying models on MediaTek platforms and want to take advantage of MediaTek’s AI-ML solutions.
Install mtk-converter
Follow the instructions to download and install the mtk-converter tool from the official NeuroPilot documentation. Install the mtk-converter tool inside a Python v3.11 virtual environment.
# Steps to start a Python virtual environment and install the mtk_converter wheel file in your Linux environment
sudoaptinstallpython3.11-venv
mkdirNP8
python3.11-mvenvNP8/
sourceNP8/bin/activate# This starts your virtual environment
pipinstallmtk_converter*.whl# Install the compatible mtk-converter wheel file. It would be part of the downloaded NP package.
pipinstall<required_dependencies># Install the dependencies as mentioned in the Neuropilot documentation
Convert Input and Output to NHWC Data Format:
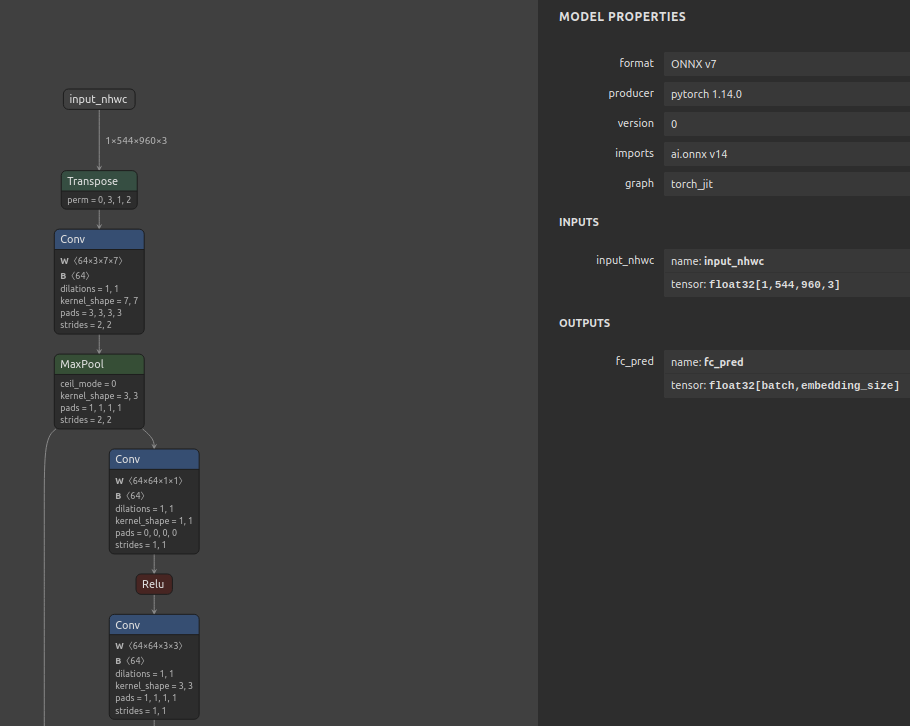
The mtk-converter by default will introduce a transpose operation to the converted TFLite model to convert ONNX NCHW data format to NHWC format preferred by TensorFlow. This might introduce overhead during execution. To avoid this overhead, we will first insert ‘transpose’ operations to the input and then continue with our model conversion and quantization.
importonnx# The provided model has one input and one outputdefadd_transpose(model_proto,nhwc_input_shape):input_nhwc=onnx.helper.make_tensor_value_info('input_nhwc',onnx.TensorProto.FLOAT,nhwc_input_shape)input_transpose_node=onnx.helper.make_node('Transpose',['input_nhwc'],['input'],perm=[0,3,1,2])model_proto.graph.node.insert(0,input_transpose_node)model_proto.graph.input.pop(0)model_proto.graph.input.insert(0,input_nhwc)onnx.checker.check_model(model_proto)returnmodel_protomodel_proto=onnx.load('resnet50_market1501_aicity156_fixed.onnx')nhwc_input_shape=[1,256,128,3]model_proto_nhwc=add_transpose(model_proto,nhwc_input_shape)onnx.save(model_proto_nhwc,'resnet50_market1501_aicity156_nhwc.onnx')
We can see in the image below that the ONNX model now has NHWC inputs and outputs
This part of the conversion consists of two steps:
Version Conversion: TAO ONNX models have IR version 9 and above, whereas mtk-converter supports ONNX models having IR version 3 to 8. So we convert the ONNX IR version to 8.
# The provided code snippet by default will convert to IR8. You can choose to convert it to any IR version between versions 3 to 8importonnxfromonnximportversion_converterdefconvert_ir_version(input_model_path,target_ir_version=8):original_model=onnx.load(input_model_path)original_model.ir_version=target_ir_versionoutput_model_path='converted_onnx.onnx'onnx.save(original_model,output_model_path)convert_ir_version('path_to_onnx_model')
Convert to TFLite: The following code snippets convert the generated ONNX model with IR v8 to TFLite.
importonnximportmtk_converterimportnumpyasnpdefconvert_to_tflite(input_model_path,output_model_path):onnx_model=onnx.load(input_model_path)# Load ONNX model to obtain input shape of model to create representative dataset for quantization.# We quantize as part of model conversion by default in this code snippet. You can choose to not quantize.input_tensor=onnx_model.graph.input[0]input_shape=[dim.dim_valuefordimininput_tensor.type.tensor_type.shape.dim]defdata_gen(input_shape):foriinrange(10):yield[np.random.randn(*input_shape).astype(np.float32)]# Create the converterconverter=mtk_converter.OnnxConverter.from_model_proto_file(input_model_path)# Set quantizer to Trueconverter.quantize=Trueconverter.calibration_data_gen=lambda:data_gen(input_shape)# If you want the model to remain in float, you can choose to uncomment precision_proportion# =====================================================# converter.precision_proportion = {'FP': 1.0}# =====================================================# Uncomment to set precision proportion to INT8# converter.precision_proportion = {'8W8A': 1.0}# Uncomment with precision proportion to set input data type as FP32# converter.prepend_input_quantize_ops = True# Uncomment with precision proportion to set output data type as FP32# converter.append_output_dequantize_ops = Trueconverter.use_per_output_channel_quantization=False_=converter.convert_to_tflite(output_file=output_model_path)input_model_path='converted_onnx.onnx'output_model_path='resnet50_market1501_aicity156.tflite'# Convert to TFLite and save to the provided output pathconvert_to_tflite(input_model_path,output_model_path)
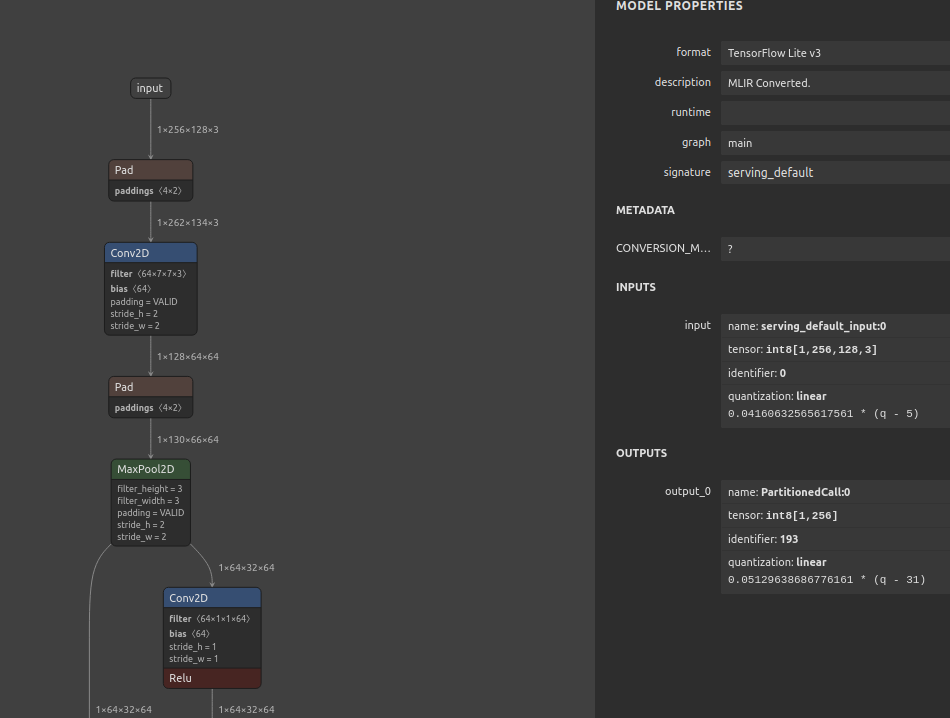
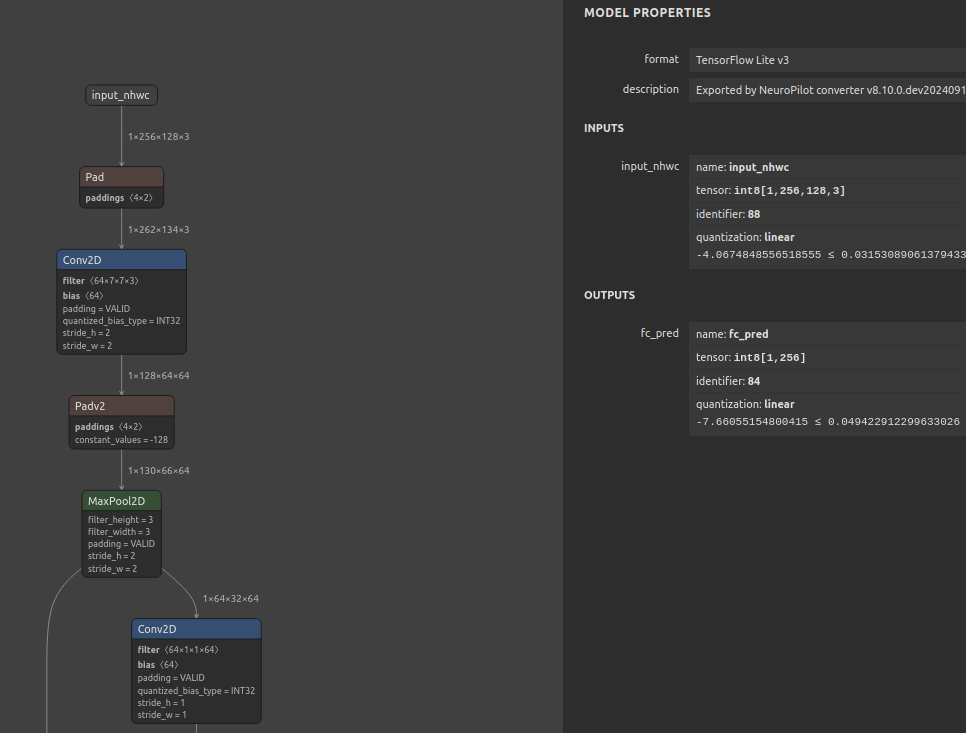
We can see the NP converted TFLite model visualized over netron below
The following table shows the inference times (in milliseconds) for the converted resnet50_market1501_aicity156.tflite TFLite model running on the Genio 700 platform.
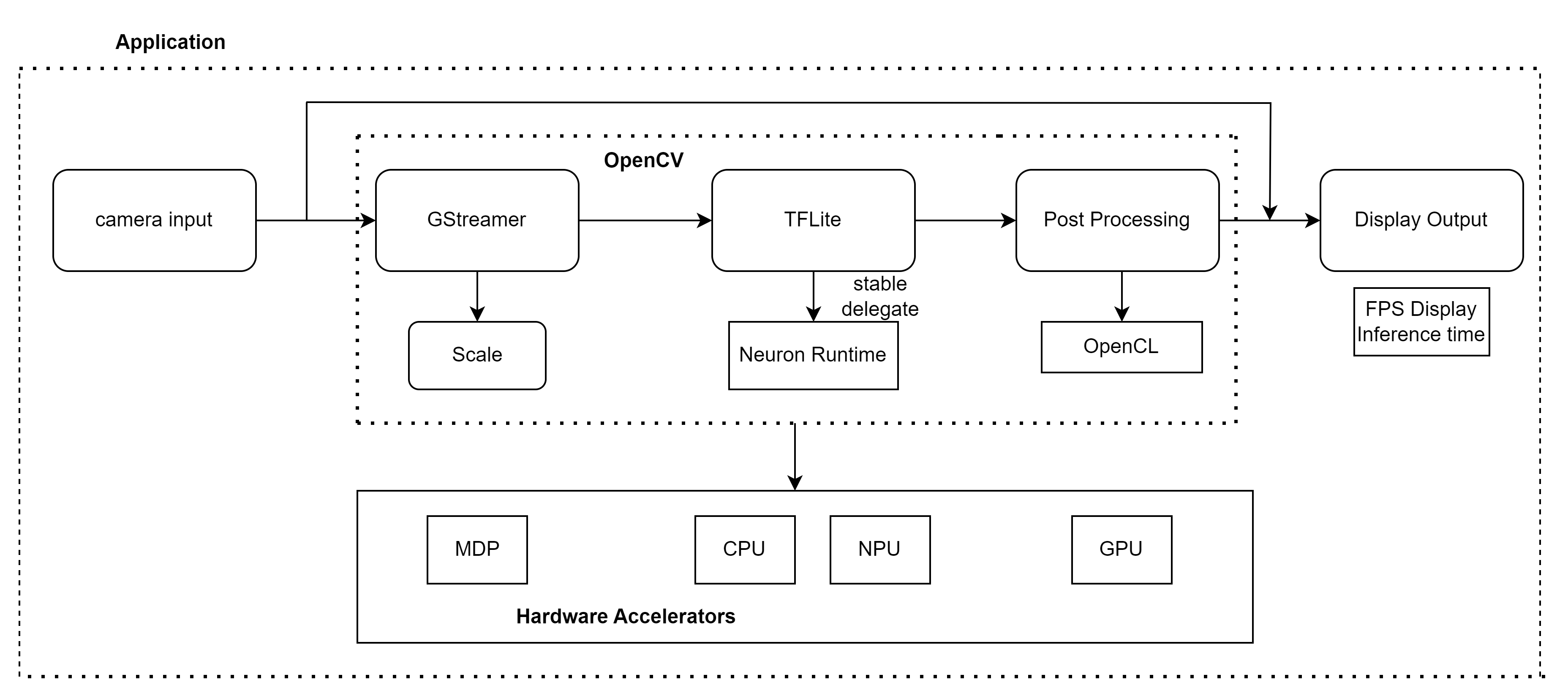
The below application performs reidentification on the person in the video and detects whether its the same person or a different person based on IDs generated. This demo works in conjunction with SSD_Mobilenet_V3 object detection TFLite model. The object detection model detects the person, and reidentification model generates the embeddings. Then the video is rerun and based on generated embeddings the people in video are reidentified.
In this tutorial, we demonstrated how to take the ReidentificationNet from the NVIDIA NGC hub, convert it to TFLite format using two different methods, quantize the model, and execute it on the TFLite benchmark model. We also showcased a demo video of an application created using the same model. This process highlights the flexibility and efficiency of using the NVIDIA TAO Toolkit and MediaTek’s Neuropilot solutions for deploying AI-ML models at the edge.