Introduction
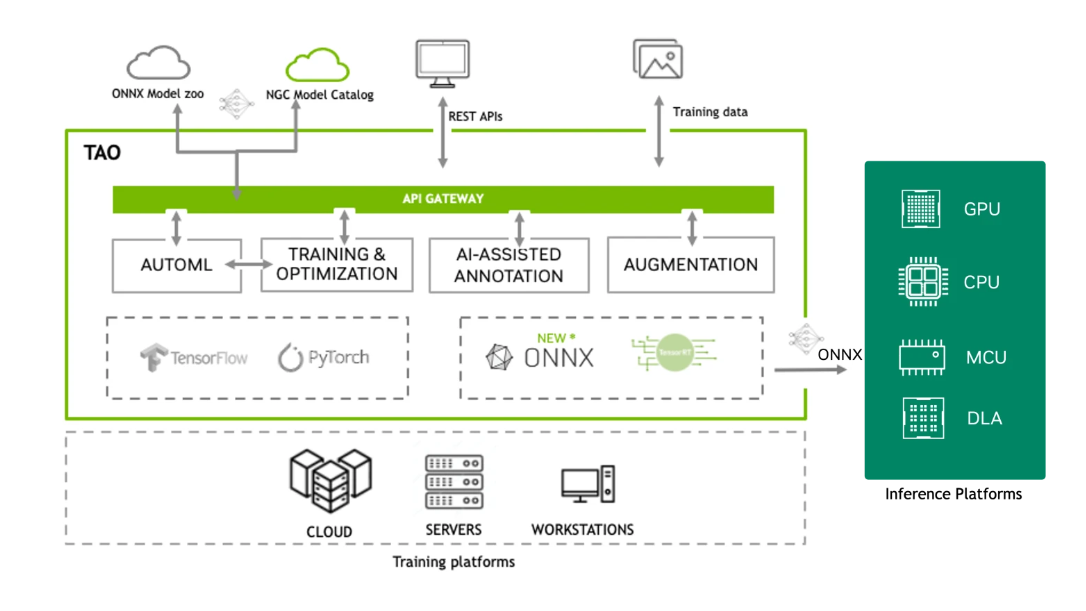
NVIDIA TAO Toolkit
The NVIDIA TAO Toolkit is an open-source platform built on TensorFlow and PyTorch. It leverages the power of transfer learning to simplify the model training process and optimize models for inference throughput on virtually any platform. This results in an ultra-streamlined workflow. With the TAO Toolkit, you can take your own models or pre-trained models, adapt them to your own real or synthetic data, and then optimize them for inference throughput. All of this can be achieved without requiring extensive AI expertise or large training datasets.
TAO TOOLKIT WORKFLOW
For more information about the NVIDIA TAO Toolkit, visit the NVIDIA TAO Toolkit website.
TAO on Genio
The Genio ecosystem is compatible with a set of pretrained models from NVIDIA TAO Toolkit. These Pretrained ONNX models can be seamlessly converted to TFLite format using NeuroPilot solutions, MediaTek’s state-of-the-art proprietary AI/ML solution. This combination of TAO and NeuroPilot provides the most optimal solution for your AI/ML needs on the edge, ensuring efficient and optimized inference on various Genio platforms.
The following Genio platforms are supported:
Genio 510 (MDLA 3.0)
Genio 700 (MDLA 3.0)
Genio 1200 (MDLA 2.0)
Combining the power of the NVIDIA TAO Toolkit with MediaTek’s NeuroPilot solutions provides a robust and efficient workflow for deploying AI/ML models on the edge. The Genio IoT-Yocto ecosystem, with its support for various Genio platforms and optimized inference capabilities, ensures your AI/ML applications run smoothly and efficiently. Whether you are working on smart home devices or industrial IoT solutions, this combination offers the flexibility and performance needed to meet your AI/ML needs.
Key Features and Benefits
Optimized Inference: The Genio platforms leverage MediaTek’s MDLA (MediaTek Deep Learning Accelerator) to provide high-performance and energy-efficient inference capabilities. This ensures that TFLite models run efficiently on edge devices.
Seamless Conversion: Neuropilot solutions simplify the process of converting ONNX models to TFLite format, ensuring compatibility and ease of deployment on Genio devices.
Versatile Deployment: The Genio IoT-Yocto ecosystem supports a wide range of applications, from smart home devices to industrial IoT solutions, making it a versatile choice for deploying AI models.
Support for Multiple Frameworks: While the primary focus is on TFLite, the Genio platforms also support other AI frameworks such as ONNXRuntime and PyTorch providing flexibility in model deployment.
Execute TFLite Models on Genio
PreTrained Models: NGC contains set of pretrained deployable ONNX models which can be directly converted to TFLite format without the need for retraining.
Model Training: Train your model using the NVIDIA TAO Toolkit, leveraging transfer learning and pre-trained models to achieve high accuracy with minimal data.
Model Conversion: Use Neuropilot solutions to convert the trained ONNX model to TFLite format. This tool ensures that the model is optimized for the Genio platform’s hardware capabilities.
Deployment: Deploy the converted TFLite model on the Genio target device. The Genio IoT-Yocto ecosystem provides the necessary tools and libraries to facilitate seamless deployment and execution.
Inference: Execute the TFLite model on the Genio device, leveraging the MDLA for optimized inference. Monitor performance and make any necessary adjustments to ensure optimal results.
Accessing Pretrained Models
NVIDIA TAO Toolkit offers a wide range of pretrained models and weights, which can significantly accelerate your development process. These pretrained models are hosted on the NVIDIA NGC (NVIDIA GPU Cloud) catalog. You can explore and download these models from the following link:
By utilizing these pretrained models, you can leverage state-of-the-art architectures and weights, reducing the time and effort required to train models from scratch.
Performance Comparison on Genio SoC
The following table shows inference performances (FPS) for various converted TAO models running on Genio 700/510/1200 platforms. The models were tested using a single CPU thread, GPU, and LiteRT NPU delegate, which provides the fastest inference times.
Model |
Format |
Genio 510 |
Genio 700 |
Genio 1200 |
|||
|---|---|---|---|---|---|---|---|
CPU |
NPU |
CPU |
NPU |
CPU |
NPU |
||
INT8 |
0.8 |
18.1 |
0.9 |
23.7 |
0.9 |
11.8 |
|
INT8 |
2.2 |
64.9 |
2.4 |
79.4 |
2.5 |
46.5 |
|
INT8 |
16.2 |
370.4 |
18.5 |
384.6 |
18.8 |
238.1 |
|
INT8 |
1.5 |
36.5 |
1.7 |
47.6 |
1.7 |
25.0 |
|
INT8 |
5.4 |
85.5 |
6.0 |
105.3 |
6.1 |
84.0 |
|
INT8 |
0.3 |
5.1 |
0.4 |
6.3 |
0.4 |
4.3 |
|
INT8 |
7.1 |
44.4 |
7.9 |
97.1 |
7.9 |
33.4 |
|
INT8 |
0.4 |
3.9 |
0.4 |
4.7 |
0.5 |
Not Supported |
|
INT8 |
7.1 |
44.4 |
9.1 |
97.1 |
9.1 |
19.4 |
|
INT8 |
10.5 |
192.3 |
11.7 |
243.9 |
11.8 |
151.5 |
|
INT8 |
7.1 |
117.6 |
8.1 |
135.1 |
8.1 |
98.0 |
|
Model |
Format |
Genio 510 |
Genio 700 |
Genio 1200 |
|||
|---|---|---|---|---|---|---|---|
GPU |
NPU |
GPU |
NPU |
GPU |
NPU |
||
FP16 |
2.2 |
4.3 |
3.2 |
5.8 |
4.8 |
5.2 |
|
FP16 |
5.7 |
14.9 |
8.1 |
19.9 |
10.5 |
24.9 |
|
FP16 |
15.6 |
86.2 |
19.8 |
123.2 |
31.0 |
115.9 |
|
FP16 |
2.5 |
9.3 |
3.4 |
12.4 |
5.3 |
12.1 |
|
FP16 |
6.9 |
25.9 |
8.0 |
36.7 |
10.6 |
38.5 |
|
FP16 |
1.0 |
FAIL |
1.4 |
FAIL |
2.1 |
FAIL |
|
FP16 |
8.9 |
FAIL |
11.7 |
FAIL |
14.9 |
FAIL |
|
FP16 |
FAIL |
FAIL |
FAIL |
FAIL |
FAIL |
FAIL |
|
FP16 |
8.9 |
FAIL |
11.7 |
FAIL |
14.9 |
FAIL |
|
FP16 |
13.6 |
60.5 |
17.1 |
87.6 |
23.9 |
62.3 |
|
FP16 |
7.5 |
31.7 |
8.7 |
39.7 |
9.3 |
40.1 |
|
Note
Assumptions:
CPU: No XNNPACK delegate, runnning on 1 CPU thread (big core)
GPU: LiteRT GPU Delegate
NPU: LiteRT NPU Delegate
TensorFlow version: v2.14
INT8 models converted using NP8 converter
FP16 models converted using TFLite MLIR converted. PeopeSemsegnet FP16 model fail on NPU becasue of INT64 output which is not supported. (To Do: convert using NP converter and restest)
FP16 Models on NPU were executed using offline conversion (TFLite -> DLA -> NeuronRT) and not using NPU delegate